GPU并行计算和CUDA编程(2)-GPU体系架构概述
并行计算
并行计算的定义: 应用多个计算资源来解决同一个计算问题
一些名词
- Flynn矩阵:
SISD(Single Instruction Single Data),
SIMD(Single Instruction Multiple Data),
MISD(Multiple Instruction Single Data),
MIMD(Multiple Instruction Multiple Data),
由 SISD,SIMD,MISD,MIMD组成的矩阵就是Flynn矩阵。从前往后,4种结构越来越复杂。 - 共享存储和分布式存储
- 通信和同步
- 加速比,并行开销,拓展性
Amdahl定律
$$1. speed rate = \frac{1}{1-P} $$
其中P是可以并行的部分,即加速比与任务中不可并行部分的大小成正比,如果完全不可并行,即P = 0,则speed rate = 1,即不加速;如果完全可以并行,即P = 1, 则$speed rate = \infty$, 即加速无穷大倍。
$$2. speed rate = \frac{1}{\frac{P}{N} + S} $$
其中N是处理器个数,P是可以并行的部分,S是不可以并行,只能串行的部分。可以看到,当N趋近无穷时,speed rate 只取决于S,即不可并行部分是系统的瓶颈所在。
GPU结构
CPU和GPU的内部结构的对比图如下: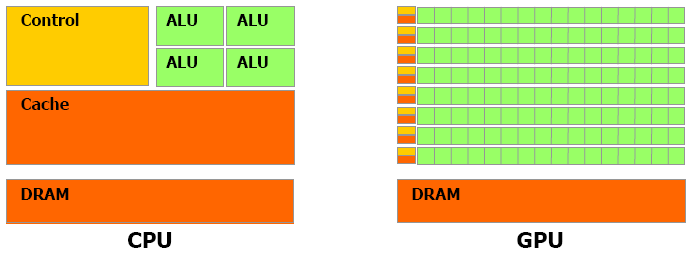
图中绿色的为ALU(运算逻辑单元,Arithmetic Logic Unit), 可以看出GPU相比CPU,多了很多ALU,而且ALU占据了内部空间的绝大部分,所以可以看出GPU是对运算很强调的芯片。
下图是一个GPU核的结构,图中所有8个ALU共用一个指令单元Fetch/Decode, 而Ctx则是每个ALU独有的存储上下文,所以,只是一种SIMD结构。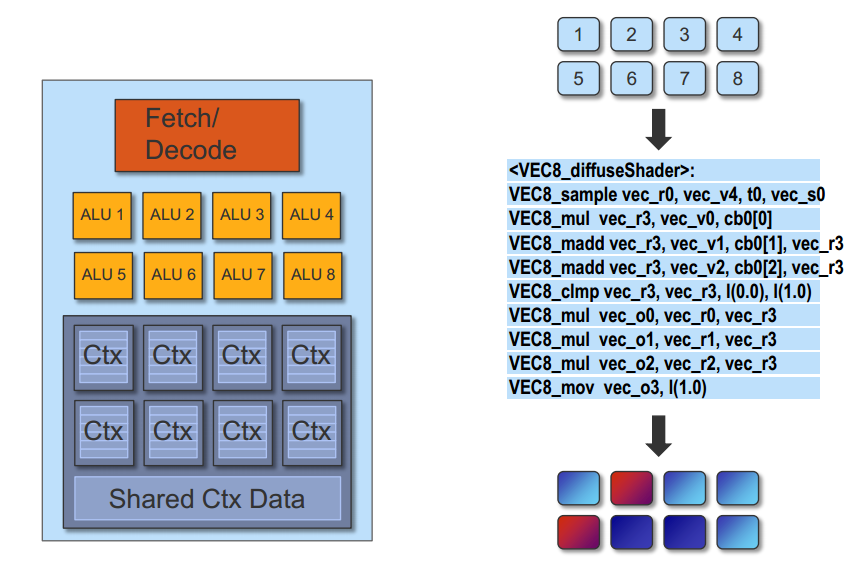
分支问题
由于每个ALU的Ctx不同,所以有可能会出现分支,这时候8个ALU的指令可能会出现分叉,即各自走了不同的路,没法共享同一个指令了,这种结构就会失效。为了解决这个问题,将所有可能出现的分支用if/else来表示,让每个ALU都进行判断,如下图所示: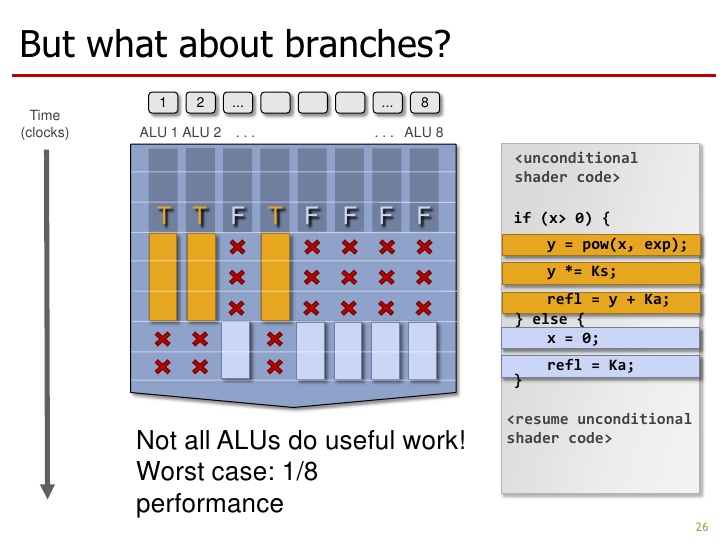
从图中我们可以看到,每个ALU都进行了if/else的判断,有的ALU走了if部分,有的ALU走了else部分,这样8个ALU就可以共用一个Fetch/Decode单元了。但因为每个ALU都要进行判断,所以做了一部分无用功,牺牲了部分性能,性能最差的时候只有1/8的有用功,即只有1个ALU选择if或选择else,其他7个ALU都做了无用功,性能只有1/8。