Attentional Pooling for Action Recognition 论文阅读笔记
这是2017年NIPS上的一篇做动作识别的论文,作者提出了second-order pooling的低秩近似attentional pooling,用其来代替CNN网络结构最后pooling层中常用的mean pooling或者max pooling, 在MPII, HICO和HMDB51三个动作识别数据集上进行了实验,都取得了很好的结果。此外作者还尝试了加入pose关键点的信息,再次提高了性能。下面我详细说明我对这篇论文的理解。
论文概况
- 论文链接: Attentional Pooling for Action Recognition
- 代码链接:https://github.com/rohitgirdhar/AttentionalPoolingAction, 采用TensorFlow和Slim来实现。
- 作者介绍:Rohit Girdhar, CMU 在读博士生,也是ActionVLAD的作者。
Second-order pooling
在CNN结构中,pooling层我们一般采用mean pooling或者max pooling,这两者都是一阶pooling (first-order pooling), 因为mean和max操作都是对feature map进行一阶操作。而second-order pooling,顾名思义,就是对feature map进行二阶操作的pooling,而这里的二阶操作,根据论文[1]中的说明,是通过feature map中的每个向量与自身的转置求外积来实现的。second-order pooling也有mean和max之分,如下面的图所示:
![Second-order mean pooling, 摘自 论文[1]](/imgs/o2p_mean.png)
![Second-order max pooling, 摘自 论文[1]](/imgs/o2p_max.png)
一个很显然的问题是,second-order pooling比first-order pooling计算量要大,因为实际实现的时候,second-order pooling须用到矩阵相乘,计算量自然比矩阵求max或求mean要大。既然如此,那会为什么还有人用second-order pooling呢?这是因为研究者发现在语义分割和细分类问题中,二阶pooling效果更好,因此为了效果提升,在某些情况下增加一些计算量还是值得的。
Second-order pooling的低秩近似
对于二分类问题,作者推导出了采用second-order pooling后输出score的计算形式,如下:
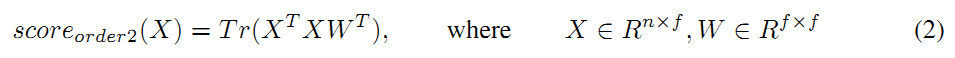
然后,对权重矩阵W进行秩为1的近似,将其表示为2个向量a和b的转置的乘积,则经过如下的推导可以得出公式如下:
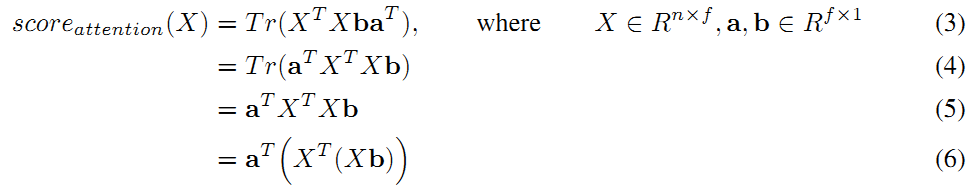
其中公式 (4) 利用了迹的性质:tr(ABC) = tr(CAB) = tr(BCA),公式 (5) 利用了性质:标量的迹等于标量本身。 进一步,公式 (6) 还可以调整为如下形式:
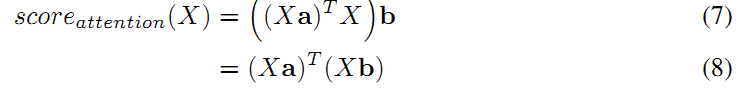
可以看到,最后的得分可以分成两部分,前一部分是输入feature map X与向量a的乘积的转置,第二部分是输入feature map X和向量b的乘积。
Top-down attention 和 bottom-up attention
以上公式推导是针对二分类问题的,对于多分类问题,只需要将参数W变为针对每个类不同的Wk即可,公式如下:
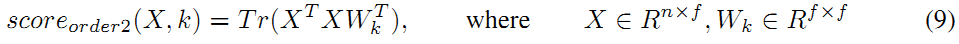
对输入X,计算所有的score(X, k), k=1, 2, ..., N,N为类别数,寻找最大的score值,对应的k即为predict的类别。
同时,对Wk也可以进行一阶的近似,将其表示为Wk = ak * b,注意ak表示向量a是跟k有关的,而向量b是与类别k无关,因此公式 (8) 可以写成下面形式: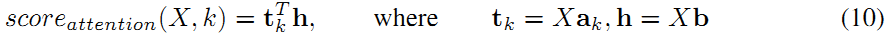
其中tk项是top-down attention而h项是bottom-up attention。作者这样分,也是受一篇2006年CVPR论文的启发,从下面的摘要可以看出(怀念750张图片就可以发CVPR的时代……), top-down attention 是用目标驱动的方式来进行visual search,而 bottom-up 则是根据图像的显著性信息来进行visual search,这种分类方式也是受到人类视觉系统的启发。

以上介绍的 top-down attention 和 bottom-up attention 合在一起就是 attentional pooling 的实现方式。
Pose-regularized attention
除了提出 attentional pooling, 作者还提出利用人体姿态关键点对attention进行约束,实现方式就是在之前网络最后加了2个MLP来预测17通道的heat map,其中16个通道时人体姿态关键点,而最后一个通道是 bottom-up attention 的 feature map, 如下图右侧中的method 2所示。 通过最小化姿态关键点的loss和 attentional pooling的loss 的加权和,使得最后的网络更好地收敛到对应的动作类别。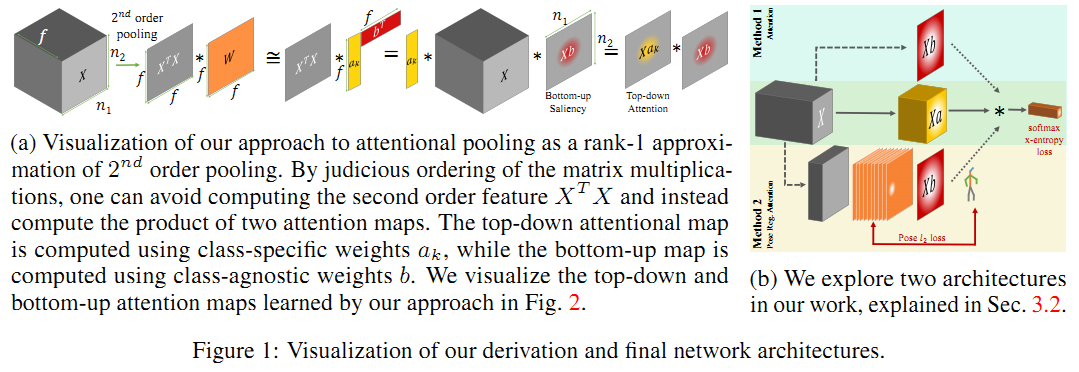
实验数据集说明
实验中采用了MPII, HICO 和 HMDB51 数据集。 需要注意的是, HMDB51 虽然是视频数据集,但是作者只在RGB数据上做了实验,而且对比的结果也只是只采用RGB数据的结果,因此在视频动作识别上最终的性能怎样,还有待验证。
MPII是德国马克斯·普朗克计算机科学研究所发布的图片数据集,具体的任务有人体姿态估计,动作识别等。数据集已经有人体姿态关键点的数据。包括的动作类别有393类,总共有15205张图片,其中训练集、验证集、测试集分别有8218、6987和5708张图片。
HICO是一个人和物体交互的数据集,包括117类动作和80类物体,训练集和测试集分别有38116张图像和9658张图像。
HMDB51是视频动作识别任务里面的一个数据集,包含6766个视频,共51类,每个视频长度3-10秒。
由于HICO和HMDB51都不包含人体姿态关键点的数据,因此实验中采用OpenPose来提取人体关键点。
值得注意的是,实验中作者将224px的HMDB51的图像缩放到了450px,这样来确保最后的feature map不至于太小(14x14), 因为太小的feature map上attentional pooling的效果不是很显著。
实现细节
1. 网络结构
实验中,作者采用了Inception-V2和RestNet-101两种网络结构,对这两种网络分别进行了不加Attentional Pooling和加入Attentional pooling后的结果对比,发现在MPII数据集上,ResNet-101性能更好,而且加入了Attentional pooling后,性能有约4%的绝对提升。
作者分析,之所以ResNet-101比Inception-V2效果要好,是因为ResNet的结构中feature map的大小下降比较缓慢,因此后面的层能学到图像不同位置的信息,从而Attentional pooling带来的增益也越多;而Inception结构在前面层上将feature map变的很小,因此后面层的感受野看到的图像范围基本都一致了,因此Attentional pooling带来的增益很小。
2. Attentional pooling 和 Pose 带来的提升
如论文中Table 1 所示,在MPII数据集上,ResNet-101的baseline的mAP是26.2%,加了Attentional pooling后mAP为30.3%,增加了Pose约束后mAP变为30.6%。可以看到pose的作用还是有一些的,但主要还是Attentional pooling的提升大些。在HICO数据集上,加了pose性能出现了下降(35.0% vs 34.6%), 在HMDB51的RGB数据上,增加pose有提升。
3. 和 full-rank pooling的比较
所谓“full-rank pooling”, 就是指使用原来的二阶pooling,不进行矩阵低秩近似。作者提到,二阶pooling计算量太大,因此采用compact bilinear approach (CBP)来近似,并且采用别人的开源代码实现,没有怎么调整参数,结果比普通的mean pooling效果要差, 自然就比低秩近似的结果也更差了。感觉这里作者的对比方法不是太规范。
4. P秩近似
我们知道低秩近似可以有很多中情况,最极端的情况就是1秩近似,即将一个矩阵分解为2个向量相乘,此外还有2秩,3秩近似。一般来说,P秩近似就是把矩阵分解为两个低秩矩阵,其中秩较大的矩阵的秩为P。论文中,对于秩为P的近似,作者采用P个bottom-up feature maps 和 C个 top-down feature maps 来相乘,这时候公式(6)就需要发生改变,Figure 1 中的Xb也变为P个,最后的结果通过对P个乘积进行求和得到。发现在秩为1,2,5的时候,在MPII数据集上的mAP分别为30.3, 29.2和30.0, 可见结果对不同的秩还是比较稳定的。
代码实现分析
作者将代码实现放到了GitHub上,但是只提供了MPII的数据和训练好的模型,HICO和HMDB51的数据和姿态关键点并没有提供,如果想好在这两个数据集上做实验需要自己提取关键点数据了。
代码采用TensorFlow 1.0 和Slim一起来实现,中间用到了compact_bilinear_pooling代码但是没有在教程中进行说明,需要在src目录下创建lib目录,自己下载这里的代码并放到lib目录下。
top-down attention 和 bottom-up attention 在Project_Root/models/slim/nets/nets_factory.py中300行左右实现,具体为如下两行:
1 | # bottm-up attention |
通过查看代码,发现作者也是用很简单的卷积来实现attentional pooling, 通过在Slim中提供的ResNet-101网络的最后面加入几个卷积层就能达到attentional pooling的效果。
另外我采用作者的代码复现的时候,发现自己训练的模型比他提供的训练好模型在验证集上的mAP测试结果要低约3个百分点,我只能达到27.6%, 而作者提供的模型能达到30.3%。原因暂时还没有找到。
一些疑问
- 作者论文中提到,为了验证方法的有效性,在视频数据集上进行了测试。但实际在做的时候,也只是在HMDB51的RGB数据上进行了实验,其实结果距离I3D等视频动作识别方法在RGB上的结果还是有较大差距的(52.2% vs 74.5%), 有效性还有待验证。
- 作者只在最后面使用了一次attentional pooling, 如果将网络中所有的pooling都换为attentional pooling,效果是否会更好?