What Makes a Video a Video Analyzing Temporal Information in Video Understanding Models and Datasets 论文阅读
概述
论文链接:点击查看PDF
作者主页:De-An Huang
论文主要目的:显式地用量化的方法来分析motion对于视频理解的作用有多大,在整个视频分析过程中起到了多大的效果。这也是我了解的第一篇用量化的方法来探讨motion信息的贡献的论文,文中逐类的分析motion带来的性能增益(图4)也是第一次见到。
这篇论文的出发点是分析在某个网络结构(例如C3D)上训练好的模型在对测试视频进行分类的时候,是否真正地用到了运动信息(motion),或者说运动信息真正起到了作用。一个简单的验证实验是在在测试视频中选一帧,然后重复N次构成一个clip(如在C3D中,N=16)。作者实验发现这种情况性能下降了25%。但这25%的性能下降不光是motion丢失带来的,作者认为这里还引入了另外两个问题:(1)改变了视频帧的时间上分布(temporal distribution),因为训练时使用的是16帧的clip,而测试采用采样过的帧构成的clip,训练和测试数据的分布不一致。(2)可能将视频中最重要的帧,对视频分类最有用的帧给丢掉了。
为了解决上面提到的两个问题,这篇论文提出了两个针对性的框架:首先是在低帧率(例如相比C3D中采用的16帧的clip,这里采用1帧的clip)的情况下,基于cycleGAN的类别无关(class-agnostic)的时域生成器(temporal generator, 英文不好,暂时这样翻译了,如果有更准确的翻译请告知)来生成帧,构成视频输入到训练好的网络中。为了使得训练收敛,作者采用了perceptual loss。第二个框架是运动不变(motion-invariant)的关键帧选择器,通过选择一个关键帧进行视频分类的任务。
具体实验是采用C3D模型,在UCF101和Kinetics这两个数据集上进行。通过使用作者提出的两个框架,使得在UCF101上,单帧clip相比16帧的clip的性能下降从25%减小到6%,在Kinetics上性能下降从15%减小到5%。同时作者用实验表明,40%的UCF101测试视频(split1)和35%的Kinetics测试视频不需要motion信息就能达到平均的分类性能。此外,在使用了作者提出的两个框架后,采用4帧的clip就能达到原来16帧的clip下的性能。至于引入的额外的计算开销作者在论文中没有进行讨论。
下面详细说明论文提出的框架和实验结果分析。
类别无关的时域生成器
为了解决训练和测试数据集分布不一致的问题,作者提出了如图1所示的框架。首先将输入视频进行下采样,实验中将16帧的clip分别采样到1,2,4,8帧这四种情况,然后将选出来的帧输入到由cycleGAN构成的时域生成器中,生成16帧的clip,通过计算生成的clip和原先的clip输入到C3D网络中得到的不同层的feature map之间的归一化的L2距离作为loss(即Perceptual Loss,感知损失)进行网络优化。整个过程是无监督的,视频的类别标签和监督损失是没有使用的,因此是类别无关的。
可能有的人会有疑问:为什么需要先采样帧,再生成帧呢,绕了一圈回来最后的效果不是和直接使用原来的帧一样吗?这样做的原因是因为模型已经训练好了,而且是采用16帧的clip训练的,而我们为了看motion起了多大作用,需要改变motion的使用情况,因此不能用全部的帧训练,而为了使得训练数据和测试数据的分布保持一致,网络需要一个合理的输入。发现说的好绕啊。抱歉了。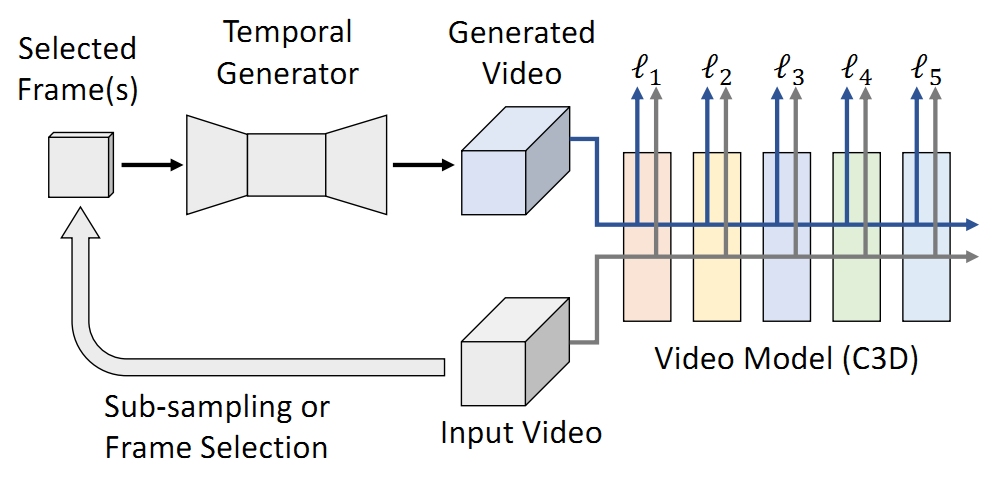
总的来说这部分是一个GAN在视频理解中的应用,用下采样的帧序列来生成完整的帧序列。
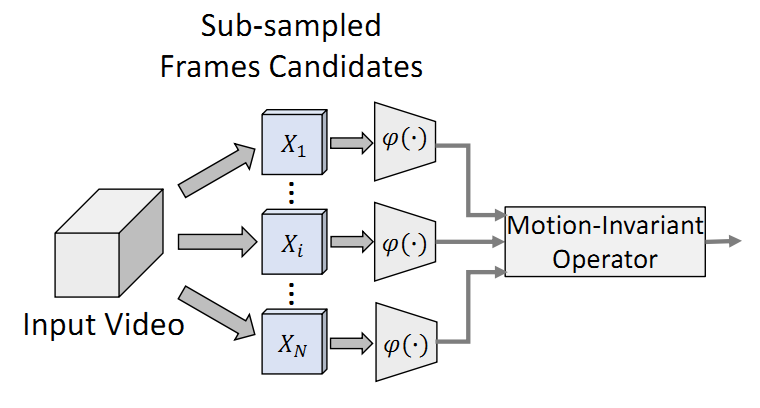
运动不变的关键帧选择器
所谓运动不变的帧选择器,就是说不管运动信息怎么变化,我得到的关键帧每次都是一样的,跟运动信息无关。满足这一点是很重要的,因为本论文就是讨论时域信息的作用,使用额外的运动信息的话这个讨论就没有意义了。作者提出了两种关键帧选择的方法。第一种是给定候选帧和一个固定的响应函数,选择响应函数的值最大(即置信度最高)的那个候选帧作为关键帧,这种选择方式作者称为Max Response。第二种是选择所有正确分类的候选帧作为关键帧(即只从候选帧中删去错误分类的帧),这种方式叫做Oracle。这种方式作者也说有些”cheating“,因为将ground truth利用了起来,而实际测试的时候ground truth是不可知的。不过这种方式也是运动不变的,没有用到额外的运动信息。帧选择器的框架如图2所示。
结果分析
如图3所示,本文的方法在采用1帧的情况下,比原先的16帧在UCF101上只差了6个点(73% v.s. 79%),而在Kinetics上则只差了5个点(42% v.s. 47%)。所以motion额外提供的信息其实作用是比较小的。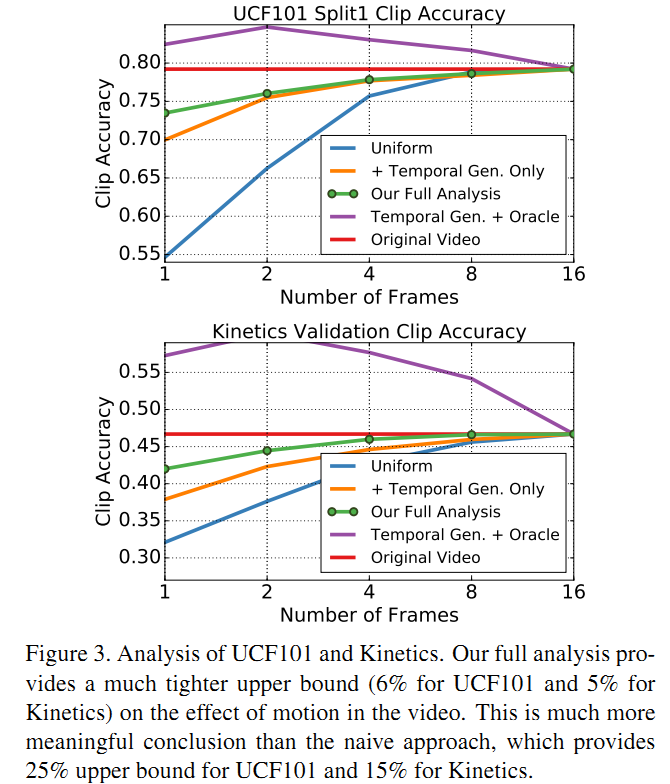
图4中展示了和原来模型相比,这篇论文中模型的准确率对比。可以发现,40%的UCF101视频和35%的Kinetics视频不需要motion信息就能达到与使用motion信息情况类似的性能。对于有些类,motion信息作用很大,而且需要更多的motion信息来进一步提高分类准确率。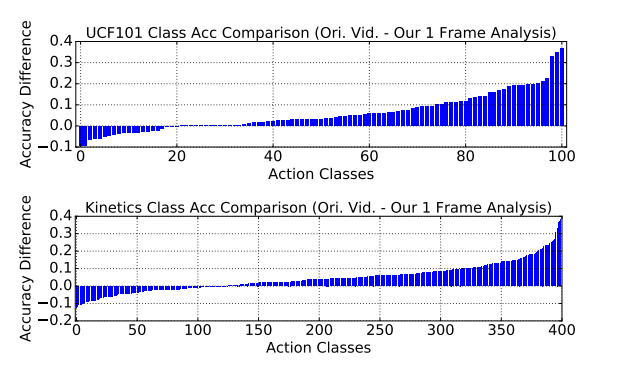
另外的分析和结论还包括:
- UCF101数据集中,最不需要motion(即只使用空间信息就足以分类视频)的类是“WalkingWithDog”,最需要motion来帮助分类的类是“PushUps”,Kinetics中的这两个类别分别是“Playing Paintball”和“JuggleBall”,看起来还是挺合理的
- 从图4可以发现,采用本方法后,4帧的clip就能达到和原先类似的性能,而本文一直强调没有引入额外的motion信息,因此16帧是有冗余的,我们并不需要所有帧来对视频进行分类
- 感知损失(Perceptual Loss)是很重要的
- Max Response能够删除噪声帧
- Oracle 比原来的模型效果更好,说明正确地帧选择方法能够提升性能,而且现有的C3D方法还是有提升空间的,因此很有必要开个新坑来探索视频动作识别中的关键帧技术
Comments
- 这篇论文第一次以量化的形式展示了具体有多少类的视频并不需要motion信息就可以很好地完成分类,我觉得比较有意义。
- 虽然这篇论文没有在数据集上有相比最好结果的提升,但是通过分析时域信息的作用,说明现有方法还是没有很好地用到motion的信息,或者说motion的作用还没有完全地利用起来,可能需要大家设计针对视频的网络结构来把motion更好地利用起来。
- 论文中的结果可视化做得很好,具体可以参考原论文的Figure 4, Figure 6 和 Figure 10。
- 希望视频理解中的关键帧选择能够在未来有大的突破。
参考文献
- CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
- C3D: Learning Spatiotemporal Features with 3D Convolutional Networks
- UCF101: UCF101: A dataset of 101 human actions classes from videos in the wild
- Kinetics: Quo vadis, action recognition? a new model and the kinetics dataset
- Perceptual Loss: Perceptual losses for real-time style transfer and super-resolution