从Numpy中的ascontiguousarray说起
1. 概述
在使用Numpy的时候,有时候会遇到下面的错误:
1 | AttributeError: incompatible shape for a non-contiguous array |
看报错的字面意思,好像是不连续数组的shape不兼容。
有的时候,在看别人代码时会时不时看到ascontiguous()这样的一个函数,查文档会发现函数说明只有一句话:“Return a contiguous array (ndim >= 1) in memory (C order).”
光靠这些信息,似乎没能道出Numpy里面contiguous array和non-contiguous array有什么区别,以及为什么需要进行ascontiguous操作?带着这些疑问,我搜了比较多的资料,在stack overflow上发现一个比较详细的回答,简单明白地将Numpy里面的数组的连续性问题解释清楚了,因此这里翻译过来,希望能帮助到别的有同样疑问的小伙伴。
2. 额外知识: C order vs Fortran order
所谓C order,指的是行优先的顺序(Row-major Order),即内存中同行的存在一起,而Fortran Order则指的是列优先的顺序(Column-major Order),即内存中同列的存在一起。这种命名方式是根据C语言和Fortran语言中数组在内存中的存储方式不同而来的。Pascal, C,C++,Python都是行优先存储的,而Fortran,MatLab是列优先存储的。
3. 译文
所谓contiguous array,指的是数组在内存中存放的地址也是连续的(注意内存地址实际是一维的),即访问数组中的下一个元素,直接移动到内存中的下一个地址就可以。
考虑一个2维数组arr = np.arange(12).reshape(3,4)。这个数组看起来结构是这样的: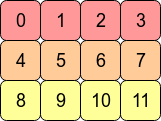
在计算机的内存里,数组arr实际存储是像下图所示的:
这意味着arr是C连续的(C contiguous)的,因为在内存是行优先的,即某个元素在内存中的下一个位置存储的是它同行的下一个值。
如果想要向下移动一列,则只需要跳过3个块既可(例如,从0到4只需要跳过1,2和3)。
上述数组的转置arr.T则没有了C连续特性,因为同一行中的相邻元素现在并不是在内存中相邻存储的了: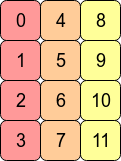
这时候arr.T变成了Fortran 连续的(Fortran contiguous),因为相邻列中的元素在内存中相邻存储的了。
从性能上来说,获取内存中相邻的地址比不相邻的地址速度要快很多(从RAM读取一个数值的时候可以连着一起读一块地址中的数值,并且可以保存在Cache中)。这意味着对连续数组的操作会快很多。
由于arr是C连续的,因此对其进行行操作比进行列操作速度要快,例如,通常来说
1 | np.sum(arr, axis=1) # 按行求和 |
会比
1 | np.sum(arr, axis=0) # 按列求和 |
稍微快些。
同理,在arr.T上,列操作比行操作会快些。
4. 补充
Numpy中,随机初始化的数组默认都是C连续的,经过不规则的slice操作,则会改变连续性,可能会变成既不是C连续,也不是Fortran连续的。
Numpy可以通过.flags熟悉查看一个数组是C连续还是Fortran连续的
1 | import numpy as np |
从输出可以看到数组arr是C连续的。
对arr进行按列的slice操作,不改变每行的值,则还是C连续的:
1 | arr |
如果进行在行上的slice,则会改变连续性,成为既不C连续,也不Fortran连续的:
1 | arr1 = arr[:, 1:3] |
此时利用ascontiguousarray函数,可以将其变为连续的:
1 | arr2 = np.ascontiguousarray(arr1) |
可以这样认为,ascontiguousarray函数将一个内存不连续存储的数组转换为内存连续存储的数组,使得运行速度更快。