dinov2_retrieval:一个基于DINOv2 的图片检索应用
1. 概述
前些天 Meta 公司发布了 DINOv2 视觉预训练模型。DINOv2 能够高效地提出图像中的特征,提取的特征可以直接用于像分类等任务,而且只需要一个简单的线性层就能取得比较好的结果。
为了展示 DINOv2 强大的特征提取能力, Meta 提供了一个在线 Demo,上传一张图片,就能从一些艺术画作中检索出最相似的作品。
拿随手拍的照片体验后,DINOv2 特征提取能力确实强大,能够准确地理解图片中的语义信息。
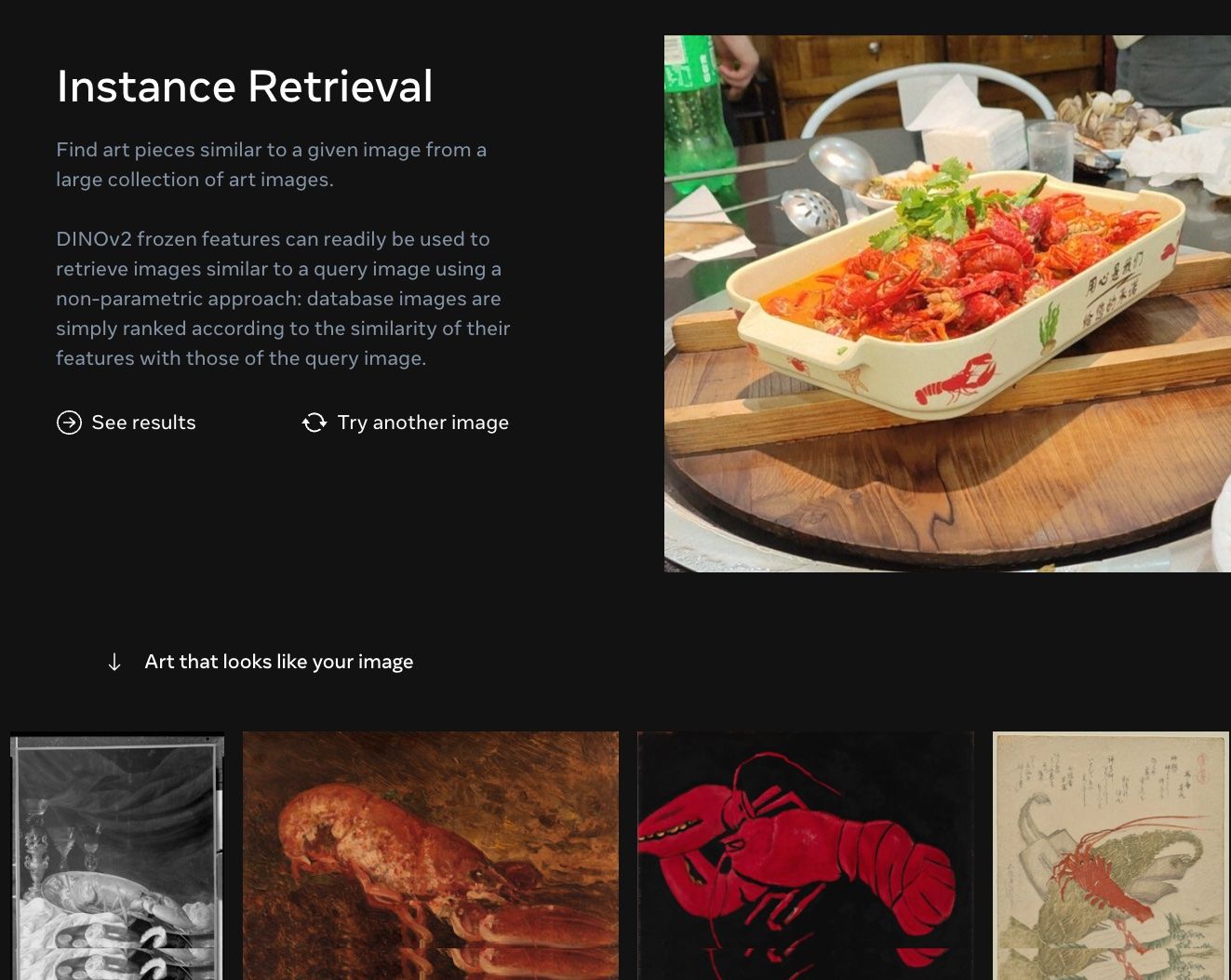
由于 DINOv2 预训练模型是开源的,因为基于它来测试实际的效果是可行的。比如,我想找到相册中跟某张照片最相似的图片,就可以用 DINOv2 来测试照片和相册中所有照片的特征,然后计算相册中照片特征与测试照片最相近的那一张,就是我想要的。
整体思路是很简单直接的,经过一天的开发,终于完成了一个相对完善的Python工具 dinov2_retrieval,能够检索若干张图片在测试数据集中最相似的图。
写完后拿最近拍的一些随机照片跑了一下,检索结果还是挺不错的。最左边是测试图片,右边的5张图是在[Caltech 256](Caltech 256)数据集中检索得到的top5相似的图像:









通过和ResNet50预训练模型提取的特征做检索对比,发现 DINOv2 提取的特征还是更准确一些,检索结果也更好。
后面部分详细说说这个工具 dinov2_retrieval 的使用。
2. 安装和使用
dinov2_retrieval 已经发布到 PyPI,因此可以使用pip来直接安装:
1 | pip install dinov2_retrieval |
安装后在命令行执行dinov2_retrieval -h 来检查安装是否成功:
1 | dinov2_retrieval -h |
如果有上面的输出说明就安装成功了,否则就有问题,解决不了的情况下可以在这里提交issue。
运行时一般来说只需要设置一下--query 和--database 参数,分别代表测试图像和数据集的地址。两者都可以是单张图片或者目录:
1 | dinov2_retrieval -q /path/to/query/image -d /path/to/database/images |
检索得到的结果会保存在output目录下。
另外的选项含义如下:
- -s/–model-size: 模型大小,可以设置small,base,large或者largest
- -p/–model_path: 模型缓存路径,一般是
$HOME/.cache/torch/hub/facebookresearch_dinov2_main,对于GitHub连接不太稳定的情况使用此选项可以从本地读取模型 - -o/–output-root: 输出结果的保存目录,默认是
output - -n/–num: 显示多少张最相似的图片,默认是1张
- –size: 图像缩放到多大来显示,默认是224
- -m/–margin: 不同图像拼接时的间距,默认10像素
- –disable-cache: 禁用database特征的cache,开启后每次运行都会对database所有图像提取一遍特征,耗时大大增加
- -v/–verbose: 开启debug log,会显示更多有用信息,比如图像的相似度等
3. 思考
写完这个工具后,有一点体会,检索这个任务要做出有意思的东西,还是要有足够丰富有趣的数据库。这也是一个通用的问题,现在的AI有强大的能力,但对于普通开发者来说,AI的能力用到哪里,怎么产生出有意思有意义的实际应用场景,是个值得思考的问题。