FastViT 论文阅读
1. 概述
论文地址:arxiv
代码地址:ml-fastvit
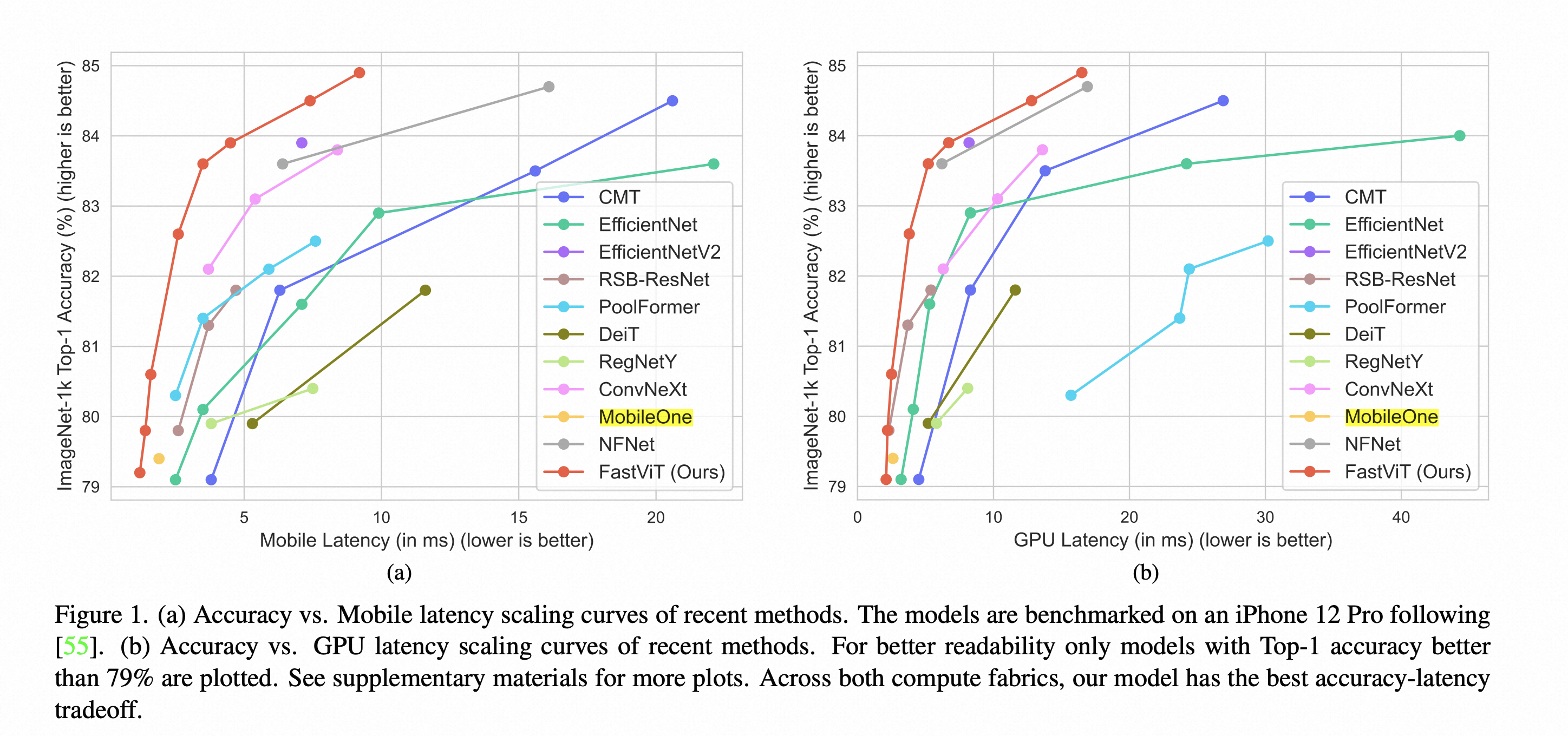
FastViT 是苹果公司在 ICCV 2023上发表的网络结构设计的论文,在速度和精度上取得比较好的折衷,速度上既能和MobileOne这种轻量级网络匹敌,精度上也不输PoolFormer、ConvNeXt等比较新的大网络结构。
这是网络整体的结构图: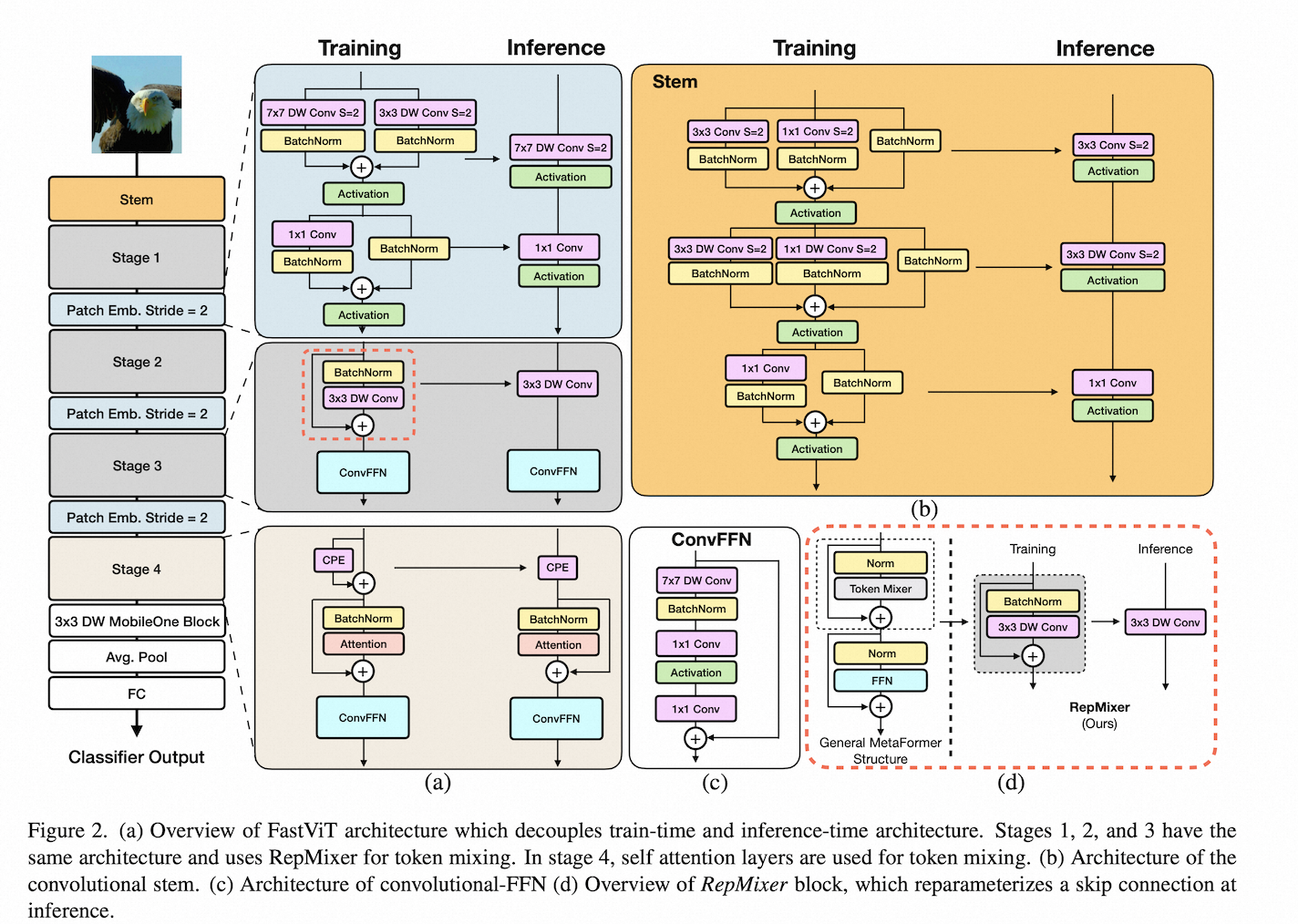
整体还是分成Stem和4个Stage,以及最后的输出Head。可以看到所有结构都在推理时进行了重参数化,保证只有一个网络分支。虽然叫ViT,但网络的核心还是由Conv层组成。
整个网络的的大部分模块是以MobileOne 的核心 MobileOneBlock 打底的,所以说是 MobileOne V2 也不为过。
比较有意思的是,FastVit 这篇论文的作者列表、作者顺序都和 MobileOne 一模一样!

所以可以说,FastViT 是 MobileOne 框架的延续,核心是在推理的时候保证只有一条网络分支,提升网络的推理速度。
具体来说,为了提升效果,网络设计上参考了比较新的 ConvMixer 结构。然后为了保证能够重参数化,将其中的非线性层省略掉,去掉残差模块。为了缓解 Self-Attention 模块计算量太大的问题,在浅层特征图比较大的情况下,采用 Large Kernel,也就是7x7 Kernel Size 的Conv网络。
下面依次对网络的几个核心模块进行说明。
2. RepMixer
ConvMixer 提出了用Conv网络替代ViT网络的方法,在效果上超越了ViT方法。
已有的一些方法已经验证,Skip-Connection因为会有额外的内存访问开销,因此会显著增加网络延迟,如果能合并Skip-Connection,对于网络的加速会有很帮助。注意论文中的Skip-Connection其实指的是类似残差模块中的两个分支相加的操作(如下图),而不是更常见的Encoder和Decoder之间的跳层连接。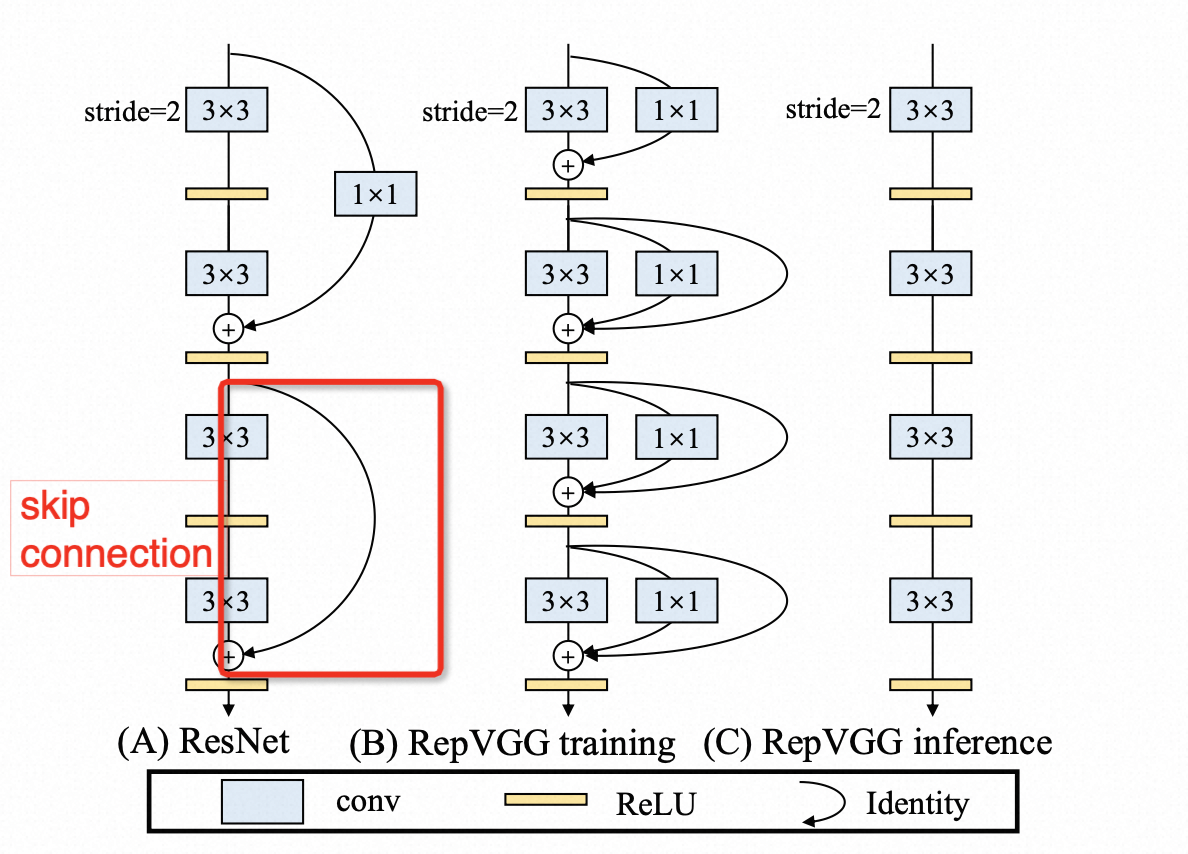
FastViT利用了 ConvMixer 网络结构优异的性能,同时为了能够在推理时进行重参数化,对 ConvMixer 进行了几个修改:
- 去掉非线性层,否则没法进行重参数化
- 将BN放在DepthWiseConv之前
- 在推理时合并 Skip-Connection,用来加速推理。
具体代码实现时,训练时采用了2个MobileOneBlock,分别表示mixer和normal,与原始输入x相加;推理的时候去掉残差相加,直接转换为一个MobileOne模块: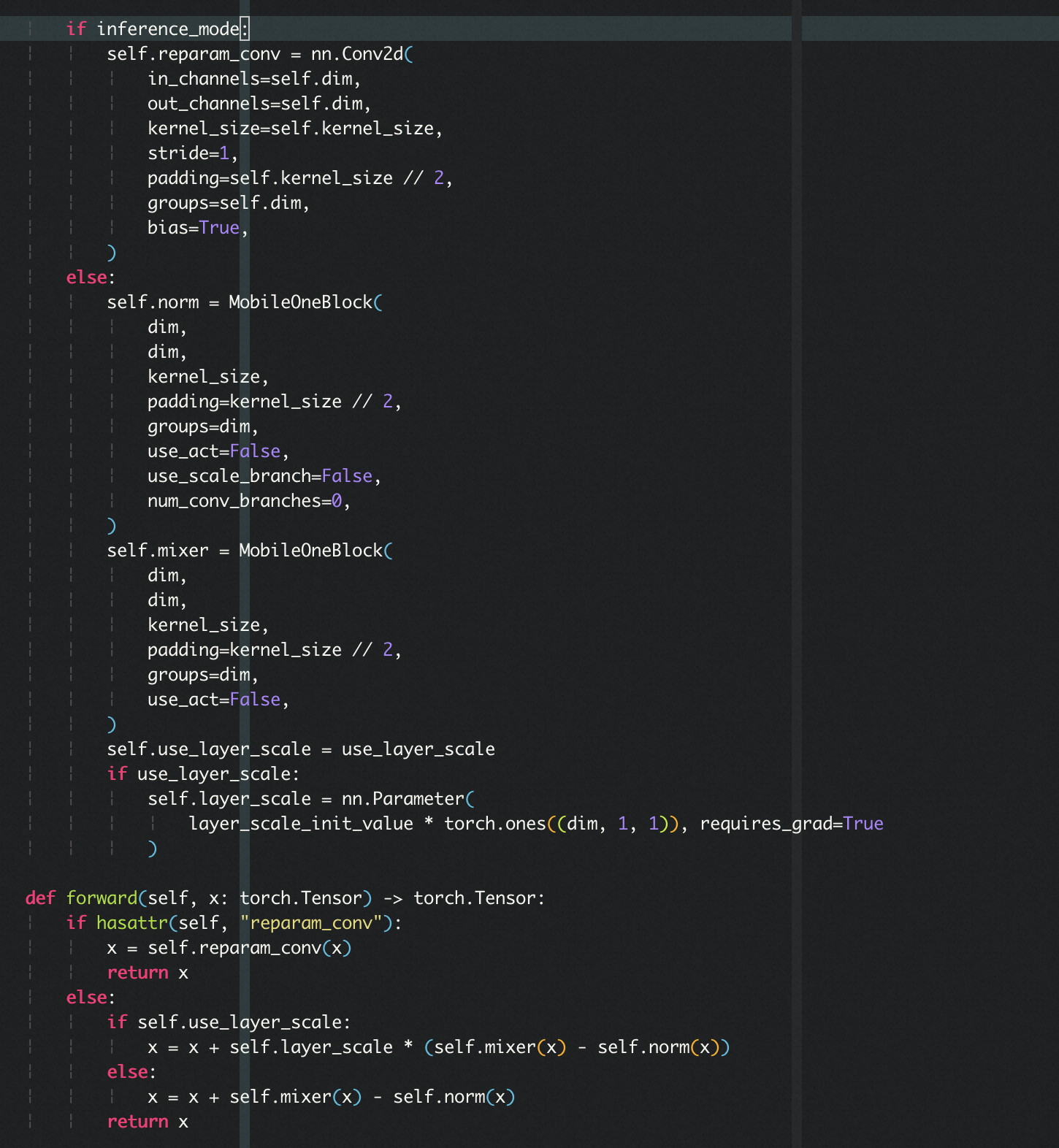
3. 训练时过参数化
过参数化是指训练的时候将结构相同的网络模块重复多遍,通过增加模型的复杂度来提点。在推理的时候,再通过重参数化trick将多个分支的结构合并到一个分支来提速。下面是过参数化的示意图(图片来自这里):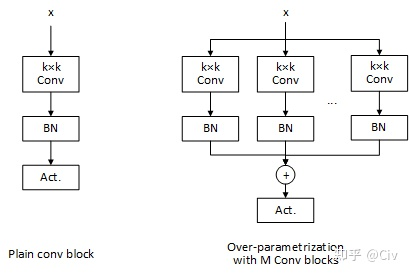
MobileOne 论文中就采用了过参数模块,验证可以提高网络的学习能力。
在这篇论文中,为了提速,先是将普通的 KxK 的Conv修改为DepthWise KxK 的 Conv + 1x1 PointWise 的 Conv层,发现在提速后精度下降,例如论文中 Table 1 所示,这步修改后耗时从 1.58ms 下降到 1.26ms,但精度也从78.5下降到78.0: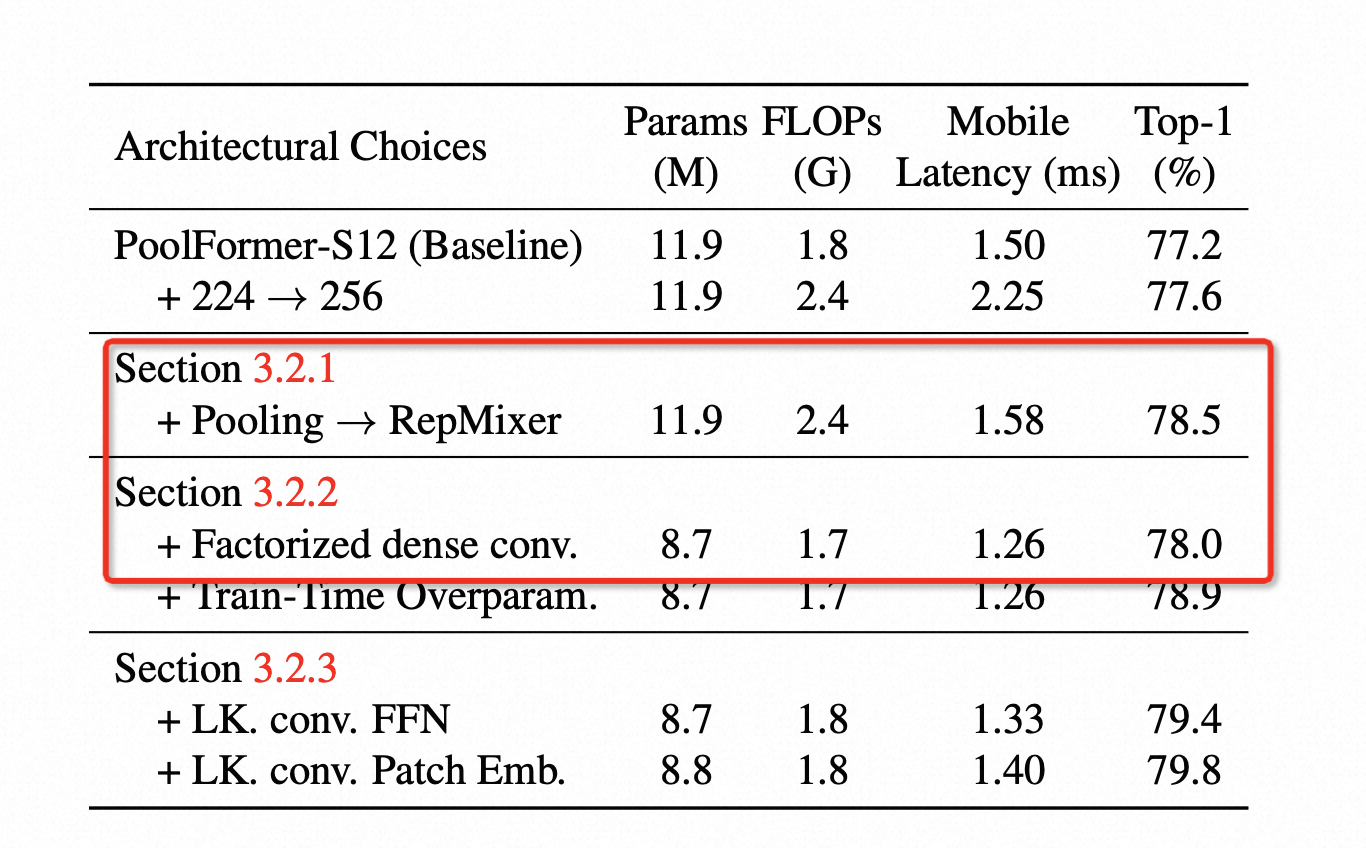
为了弥补这一步造成的精度损失,作者叠加了上面提到的训练时重参数化的trick,保证速度不变的情况下,效果超过了之前的方法,从78.0上升到78.9。
当然这部分的结构优化其实比较”水”,是现有的两个工作的简单组合……
4. Large Kernel
由于Transformer结构的核心模块是Self-Attention模块,而且已经被无数实验验证具有强大的特征提取能力。
但Self-Attention的计算量很大,要做到手机上实时难度不小。
作者认为,Self-Attention 效果好跟它有很大的感受野有关系。而普通 Conv 层通过增加 Kernel. Size,也能达到提高感受野的效果。
因此最终网络结构设计上,在每个Stage开始的时候,采用 7x7 的 MobileOneBlock。7x7 的 Kernel Size 也是通过实验试出来的。
为了既能跟MobileOne这种轻量级网络对比,又能在 ImageNet 上和别的模型一较高下,论文中提出了7个 Fast-ViT的变种,各个变种的设置如下: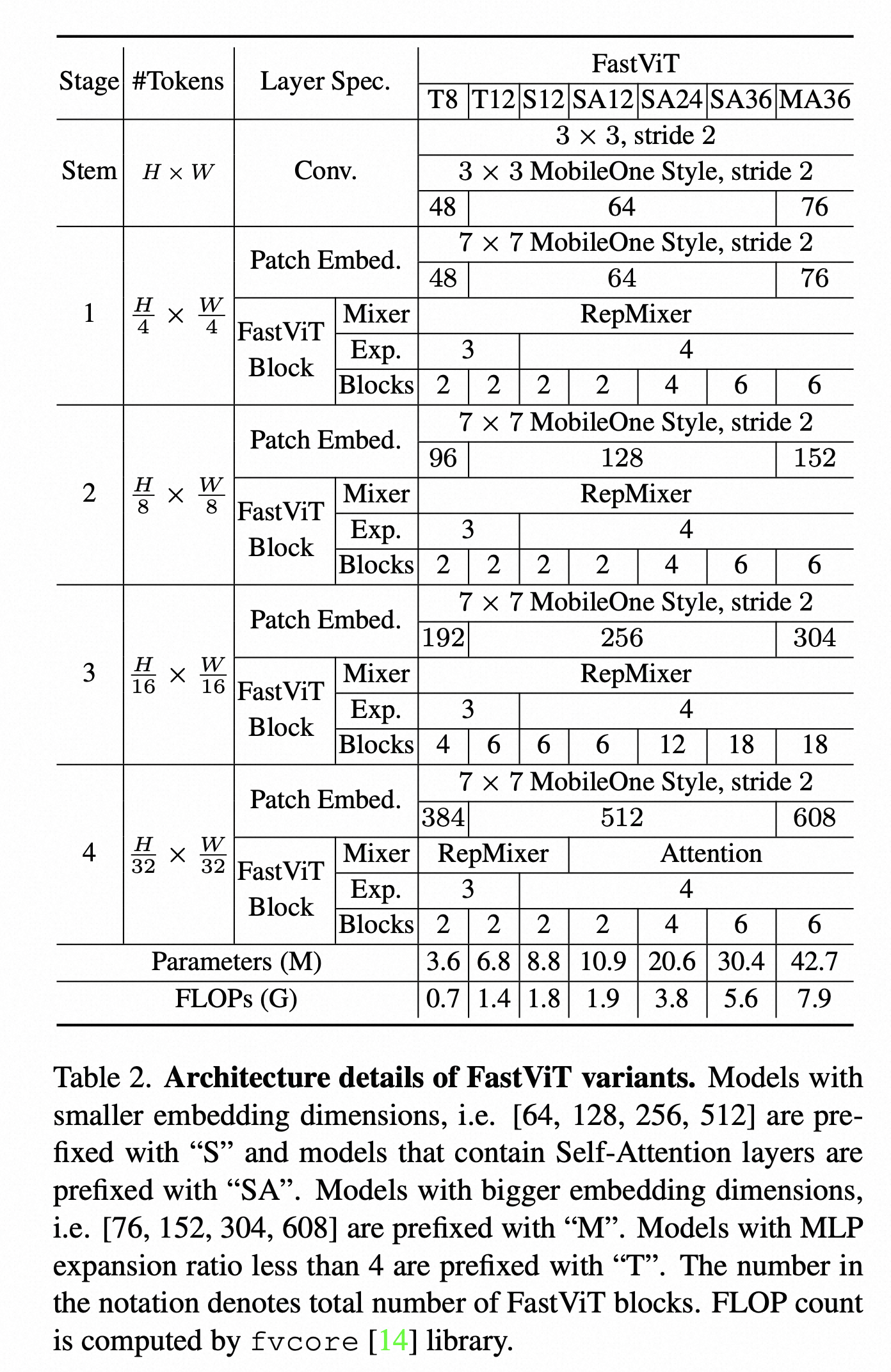
5. 实验
对比实验在 ImageNet-1K 分类任务、COCO 物体检测,ADE20K 语义分割等标准任务上进行了对比
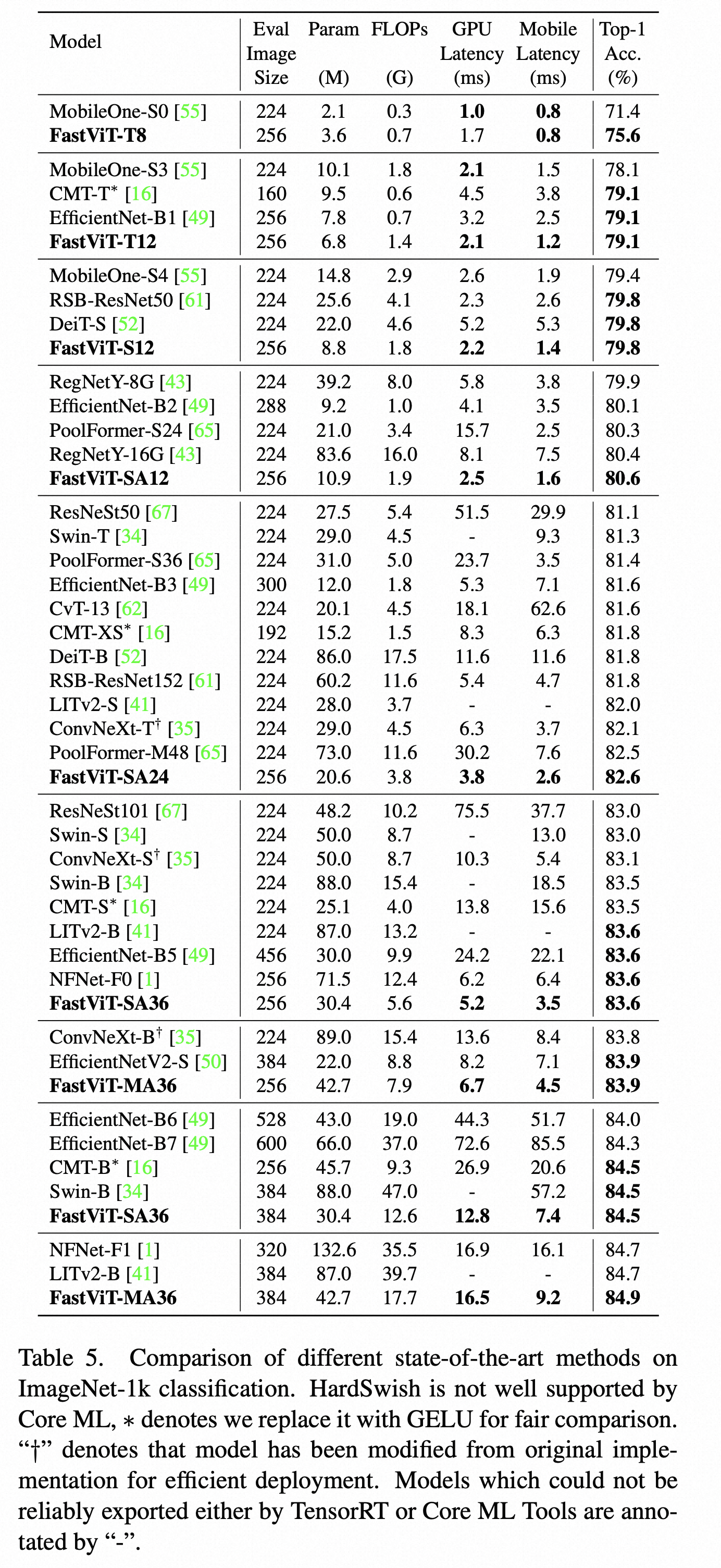
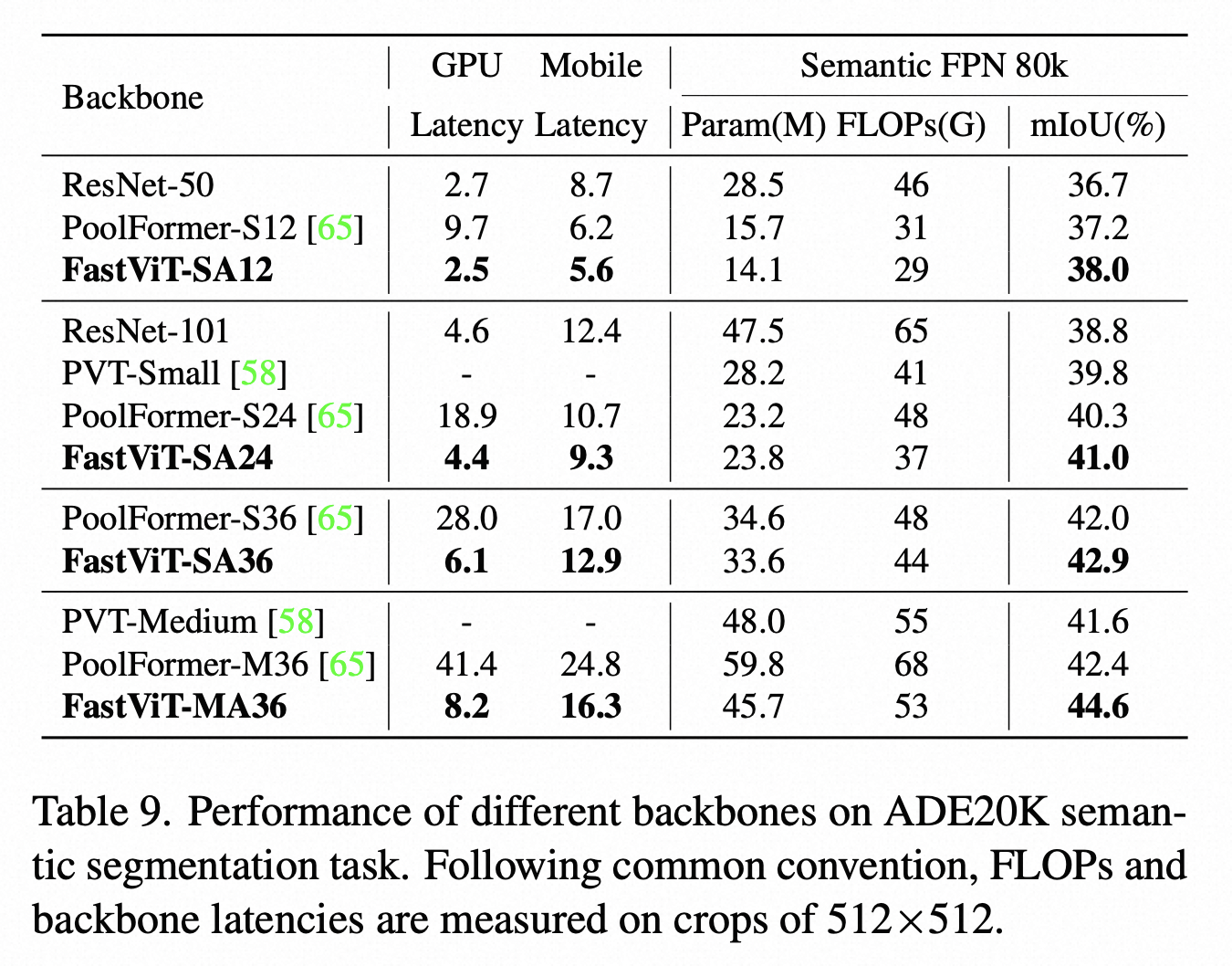
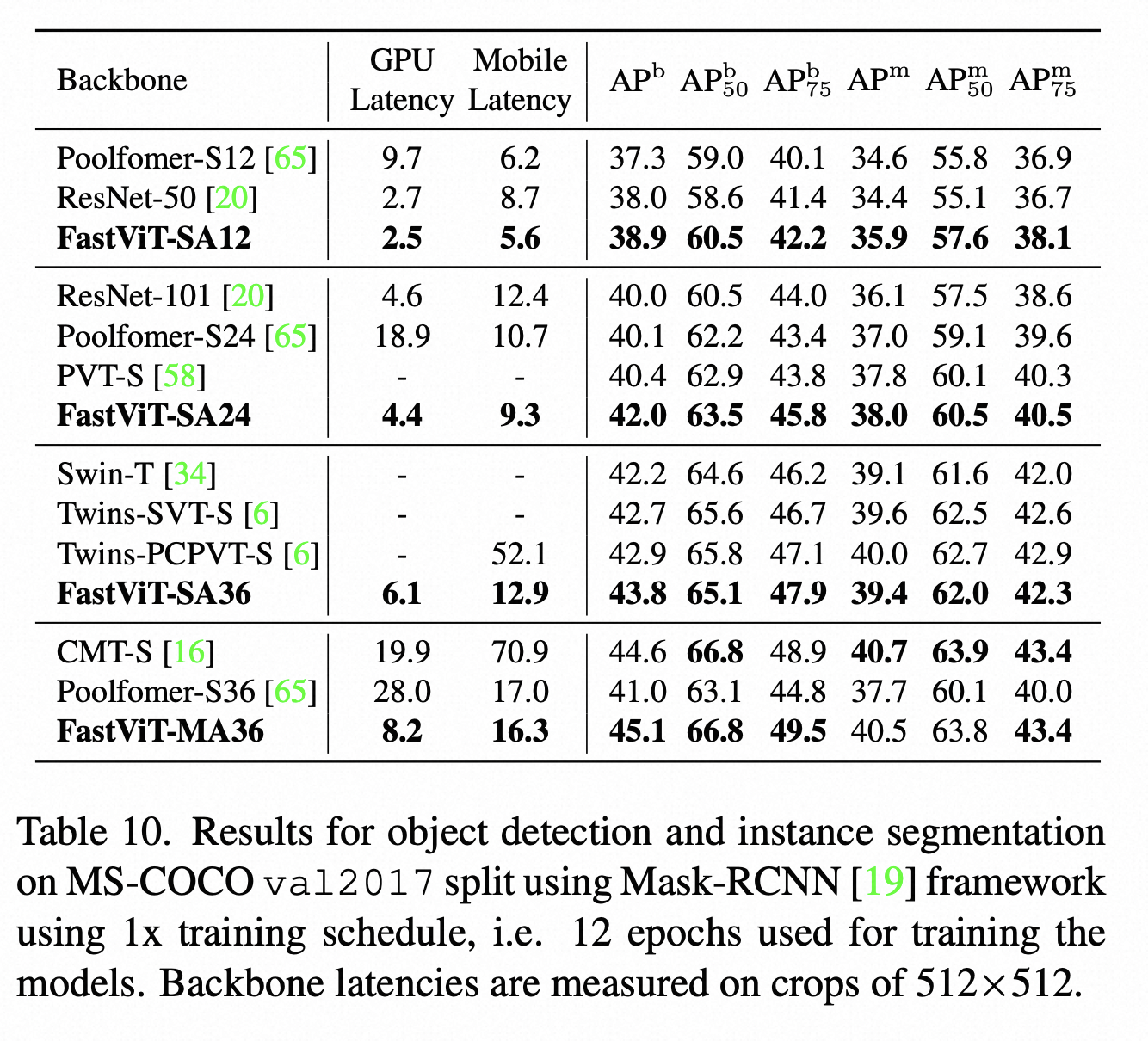
另外这篇论文还比较了FastVit在3D手重建这个下游任务上的效果,也是比MobRecon这些端侧实时的方法效果更好,当然还是刷不过MeshGraphormer等基于HRNet Backbone的模型。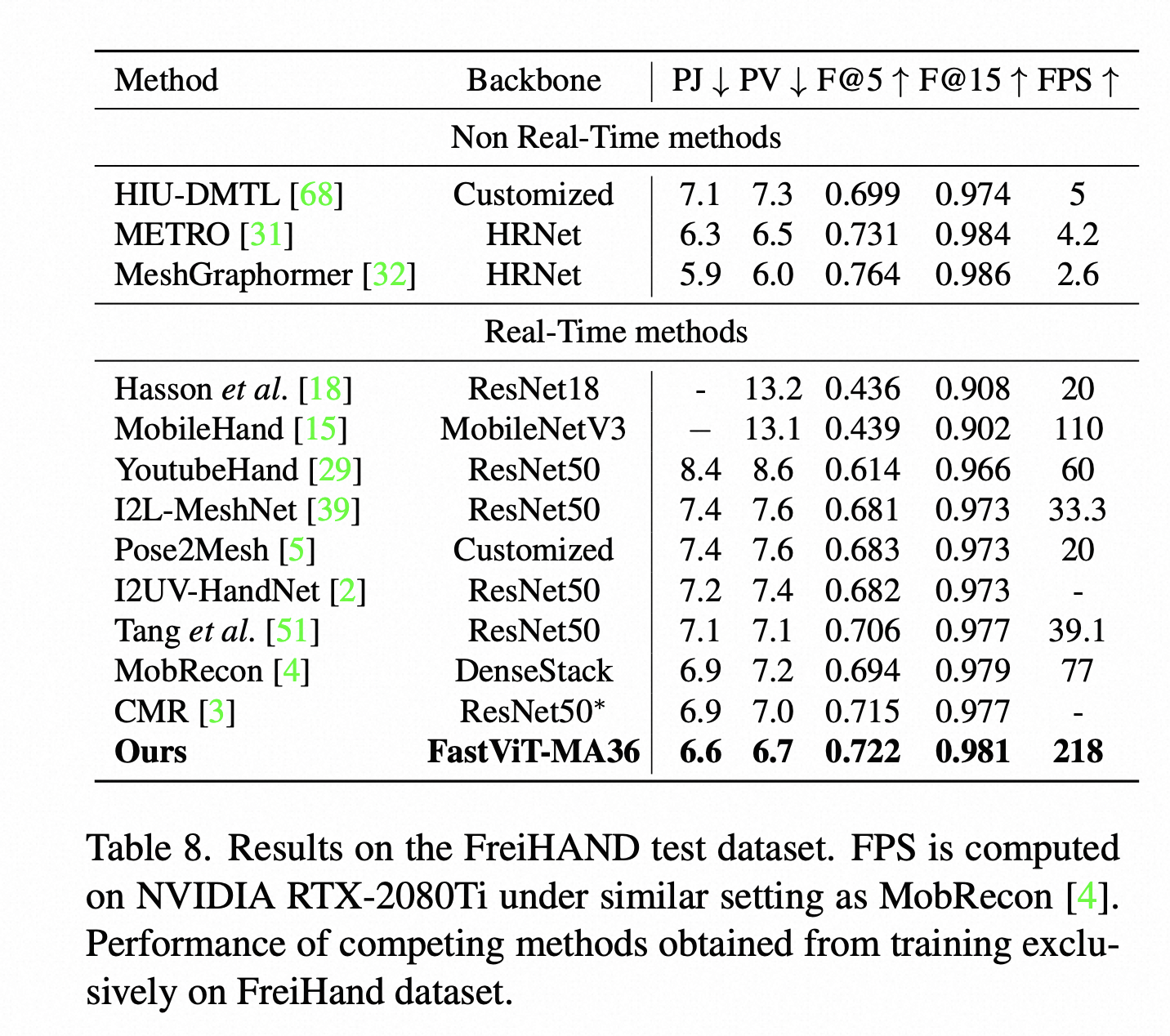
6. 总结
整个论文是比较实用的,没有太多自己的原创性的点子,更多的是将一些现有的网络结构设计思想融合进MobileOne的推理时单分支的网络结构中来。
另外一个值得注意的事情是,论文中给出的Mobile Latency都很低,像 FastVit-MA36 7.9G 的FLOPS,移动端延迟4.5毫秒。但要明白这是用iPhone 12 Pro Max上使用CoreML来测试的,本身iPhone 12 Pro Max 采用的A14芯片很强,而且CoreML针对苹果的硬件有专门的优化,所以在安卓机器或者低端一些的iPhone 上,采用别的推理引擎(如ONNX, MNN, TCNN)进行推理时,很有可能达不到这么高的速度,所以像 FastVit-MA36这种FLOPS 约为8G的模型在手机上用起来还是需要验证的。
总之对于想试用 FastViT 的小伙伴来说,用就完了,代码已经开源,也不存在复现的问题,直接用起来,好用就加入到自己的任务中,效果比较差或者速度有瓶颈抛弃即可。
另外 FastViT 的代码实现很简洁优雅,阅读起来很舒服,后面有空可以写一篇代码阅读的文章,欢迎感兴趣的小伙伴关注、点赞和评论区留言~