hangzhou-line1-benchmark-一个简单的图片理解问题集
0. 概述
最近qwen2发布了多模态系列模型Qwen2-VL,查看blog发现,72B的模型在很多benchmark上都超过了GPT-4o,而根据之前的经验,标准测试集上的效果与实际使用体验并不总是一致的。之前在某个多模态模型出来的时候,随手拍了一张地铁线路图做测试,发现效果不尽如人意。这两天花时间将这张地铁线路截图中的问题进行了标准化,构建了一个简单的图片理解测试集,让我们看看Qwen2-VL到底行不行。
1. 测试问题构建
为了保证测试问题构建简单,只围绕下面这张地铁截图进行问题设计,所以考察的并不是模型的综合能力,而是考察日常生活中的一个小的实际场景下的效果的好坏,这样有点以偏概全,但这种随机的场景上的明显提升,才能真正体现模型的能力。
另外实际问题时也跟标准测试集不同,尽量口语化,非标准化,不会像法律文书那样精准描述,这也是为了模拟日常对话的情况。
总共10个问题:
仅根据上传截图中的信息,回答下面问题:
这张截图显示的是几号线
这张截图总共包含了多少个地铁站
这站截图的地铁站中,总共有多少个换乘站
当前是在哪个站
沿着红色箭头方向,闸弄口的下下站是什么站
终点站是哪个站
从彭埠到龙翔桥,总共要坐几站(包含彭埠和龙翔桥)
图中的地铁线路与5号线有几个换乘站
有几个站可以坐火车
图中的地铁线路总共可以几条线路换乘
这10个问题考察模型下面几个方面的能力:
- 文字识别理解,如地铁线路编号,
- 图片理解,如换乘标识,火车logo,箭头方向
- 推理能力,如从站A到站B总共要坐几站
- NLP能力,如”下下站”(发现大多数模型没理解这个词)
- 多维度理解能力,例如结合箭头方向和线路图,寻找下下站是哪一站
为了保证模型的分数可以量化,这里选择的都是确定性问题。
得分情况是答对一题算一分,否则算0分,因此满分10分,最低0分。
2. 测试模型说明
为了保证测试的简单,这里只对比了几个PC 网页端可以访问的多模态模型,测试日期为2024-09-01, 具体访问网址如下:
- 豆包:https://www.doubao.com/chat/
- Kimi.ai - 帮你看更大的世界 (moonshot.cn)
- 讯飞星火:讯飞星火大模型-AI大语言模型-星火大模型-科大讯飞 (xfyun.cn)
- 智谱清言:https://chatglm.cn/
- GPT-4o mini: API
- Qwen2-VL-7B: 千问2多模态视觉模型-7B体验空间 · 创空间 (modelscope.cn)
- Qwen2-VL-72B: Qwen2-VL-72B - a Hugging Face Space by Qwen
除了GPT-4o mini,别的模型都可以直接点击网址进行体验。
测试方式很简单,访问网页,新建对话,上传图片,将上面的问题粘贴进去,回车等待结果。
3. 分值量化
先上总的结果表格:
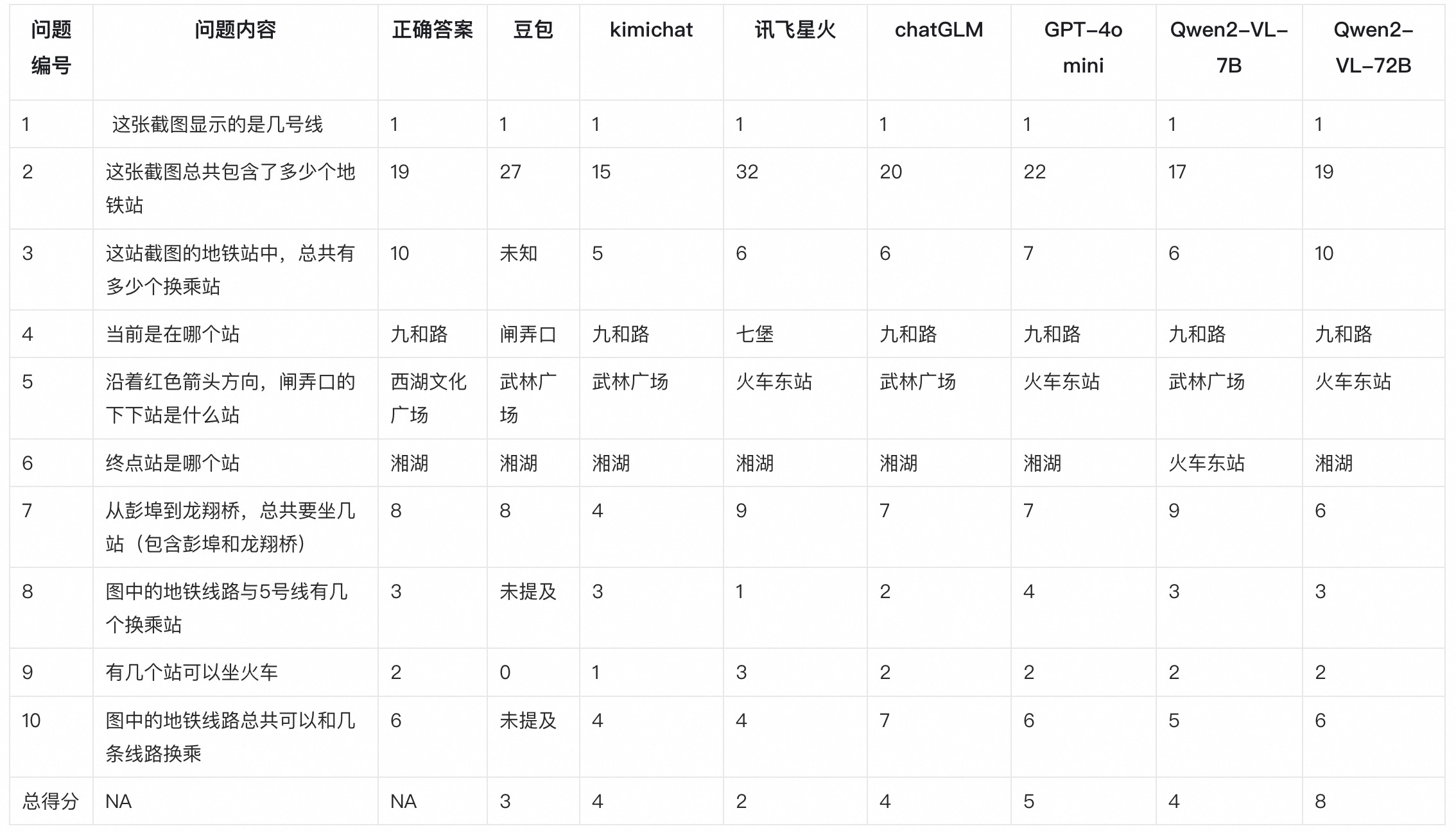
可以看到最新发布的Qwen2-VL-7B还是比较一般,只有4分,Qwen2-VL-72B效果提升很明显,从7B的4分提升到了8分,也是几个模型里面唯一及格的。
具体每个模型的回答截图如下,供参考。
4. Qwen2-VL-72B 的解题细节
QWen2-VL-72B真的这么强吗,为了进一步分析,我让它不光返回结果,还对中间的分析过程进行说明,结果如下:
发现结果答对的题目中,有几个题目分析结果并不对:
- 第3题中,换乘站少了近江,多了闸弄口
- 第8题中,换乘站多了一个火车东站,少了一个打铁关
所以说,其实qwen2蒙对了2道题,或者说中间解题过程有错误,如果只考最终结果,能得80分,如果要写中间过程,那估计只能得60分了。
另外通过中间回答,发现它对“下下站”的理解不对,理解成了下一站,但单独问,却能正确回答:
另外多维度联想能力不太好,例如第7题目,沿着红色箭头方向,应该是从下往上的方向,但Qwen2-VL-72B搞反了。
5. 总结
到这个程度,我觉得多模态模型差能够解决一些日常生活中的推理问题了,玩起来会更有趣一些。问题和图片放到这个仓库了,后面出来新的模型还会继续用这个hangzhou_line1_benchmark进行测试,希望我的这个简单测试问题集早日被打爆。