Comma v0.1 -全开源数据训练的可复现大模型
credit: via
近期,Common Pile 团队开源了利用开放数据训练的7B LLM模型Comma v0.1 1T和2T,训练数据采用的是这个团队采集的Common Pile v0.1,1个8T的数据集,包含公开数据,以及开放证书的数据,也就是训练大模型都是合法的,没有采用带版权的数据。
博客文章:https://huggingface.co/blog/stellaathena/common-pile
论文地址:https://arxiv.org/abs/2506.05209
训练数据地址:https://huggingface.co/datasets/common-pile/comma_v0.1_training_dataset
模型权重:
Comma v0.1 1T:
- safetensor格式: https://huggingface.co/common-pile/comma-v0.1-1t
- mlx格式: yunfengwang/comma-v0.1-1t-mlx
Comma V0.1 2T:
- safetensor格式: https://huggingface.co/common-pile/comma-v0.1-2t
目前开放了Comma v0.1 1T和2T 2个模型,都是7B量级的,基于Llama3 架构。1T是在1T的数据上训练的,2T采用了2T的训练数据。
注意:这个模型暂时只支持英文,别的语言效果比较差。
比较可贵的是,团队也将训练配置文件开放了出来。训练框架是lingua,训练的配置文件在这里。
下面是1T和2T版本和之前的模型的结果对比,Qwen3指的是是Qwen3-8B。在某些任务上,跟Qwen3-8B差距还是很大。
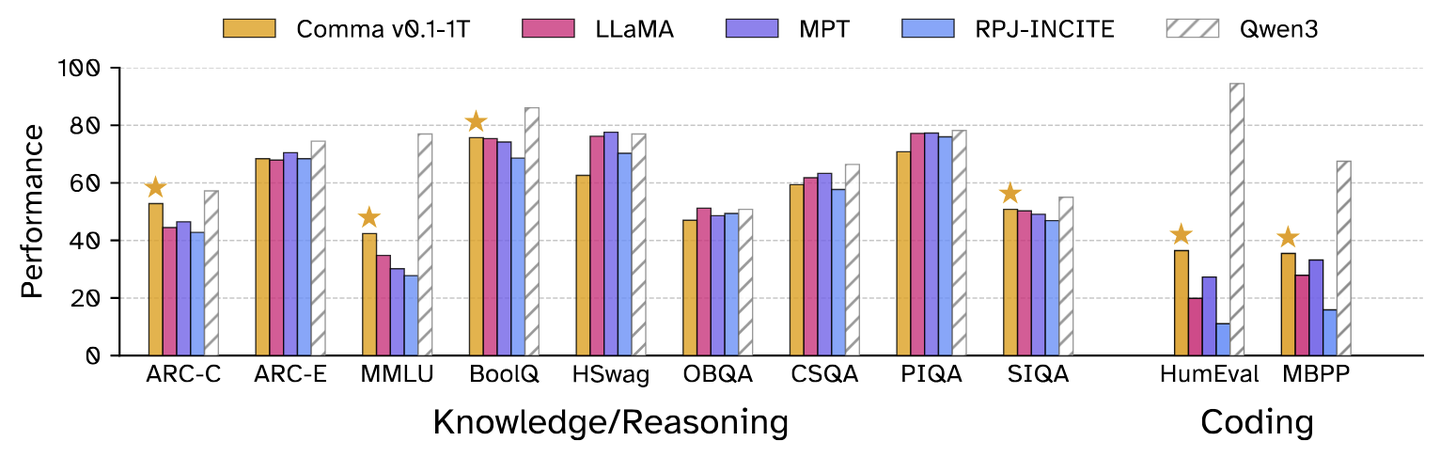
添加图片注释,不超过 140 字(可选)
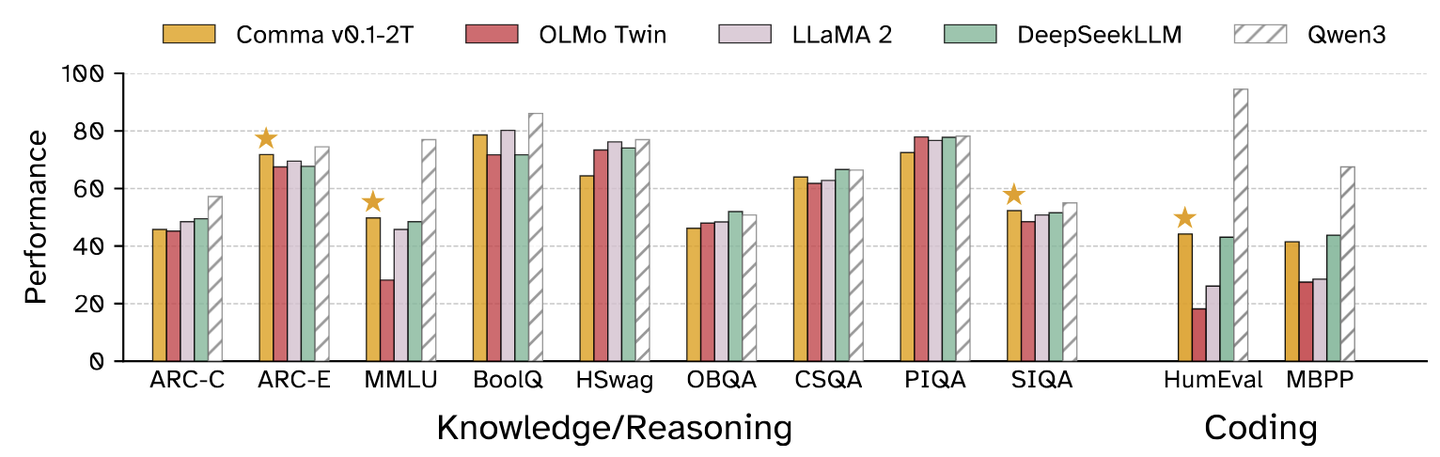
添加图片注释,不超过 140 字(可选)
另外需要注意:目前给出的模型还是base模型,不是instruct模型。
那么具体该如何体验呢? 最简单的尝试方式是采用mlx框架来在mac上测试,可以用下面的一条命令(先pip 安装uv):
1 | uv run --python 3.12 \ |
这是AI透明化道路上的一小步,效果虽然还比较一般,但走在正确的道路上。希望以后能看到更多数据合法开放、训练过程公开、模型权重开放的AI模型。