Qwen VLo 效果实测
2025年6月26日,Qwen团队发布了Qwen VLo,一个定位是“unified multimodal understanding and generation model”的模型,包括多模态的理解和生成。
根据官方的介绍博客,Qwen VLo包含下面的功能:
- 图像生成:文生图、2D卡通图像转真实图像
- 图像编辑:例如修改某个主体、更换颜色、更换风格
- 图像算法能力:例如检测框、canny 算子、图像分割结果
经过一段时间的测试,我个人的总结是:
- 生图能力:效果比较差,感觉是一两年前生图模型的水平
- 图像风格转换:效果比较稳定,生图有美感
- 图像编辑能力:还算可以,有一些case做不好
- 检测框:能稳定生成,单人没问题,多人场景下也不算很准
- 图像分割:没有成功
- canny算子:细节更丰富,但有一些地方与原图并非完全对齐
再单独吐槽一个点,刚开始没找到Qwen VLo的入口,看微信公众号文章的留言才发现,并不是以一个模型列在可选模型列表中的,而是不管选择什么模型,只要做生图任务或者上传图片进行对话,都调用Qwen VLo。这种不遵从用户已有习惯的设置,随意而为的做法,用户体验很差,要是没看到留言回复,真的不知道怎么用。
下面详细展开我上面总结中各个条目的实际结果。
1. 生图
用最简单的提示词来生成图,下面是一些结果和对应的提示词。
Prompt: 画一个哪吒

Prompt: 画一个哪吒
Prompt: 画一个哪吒骑在龙上的照片

Prompt: 画一个哪吒骑在龙上的照片
没有处理好”骑”这个动作。
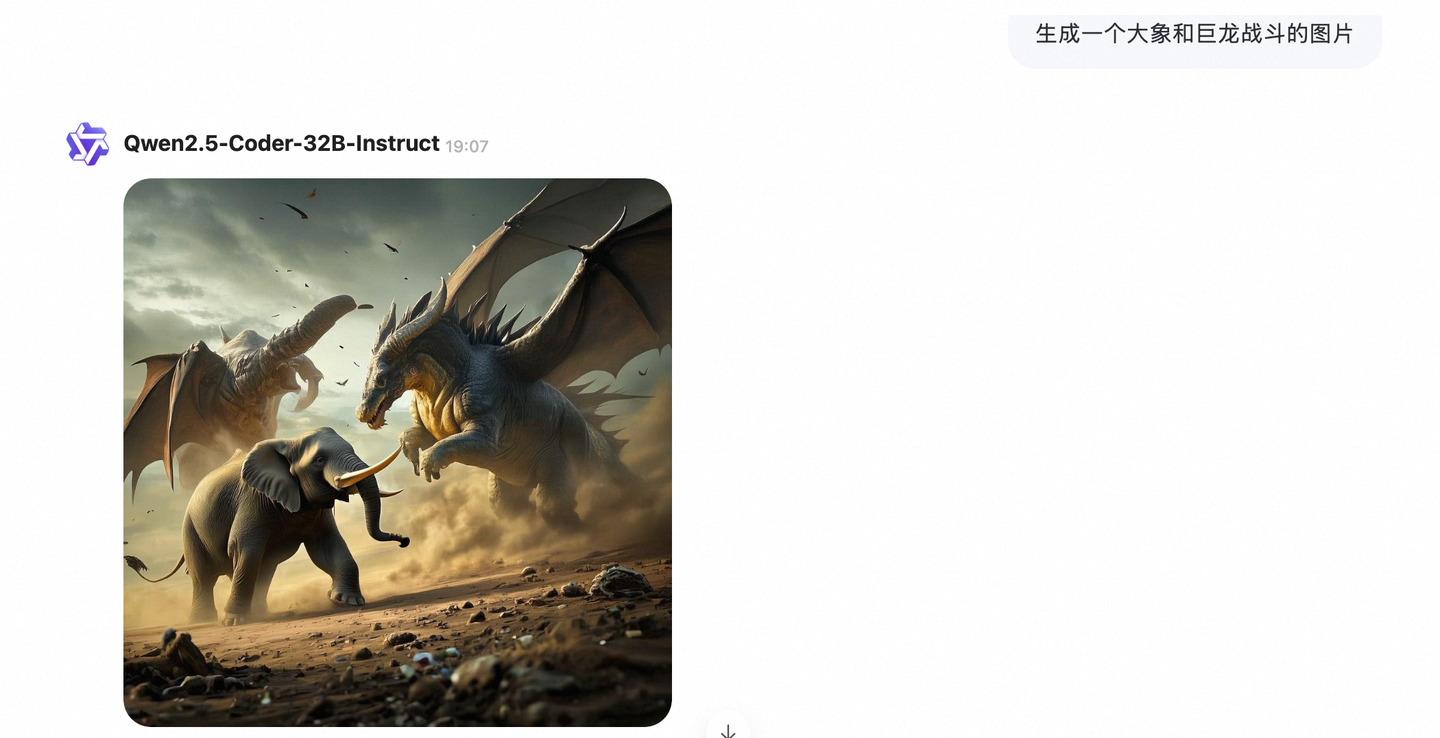
Prompt: 生成一个大象和巨龙战斗的图片

Prompt: 生成一个大象和巨龙战斗的图片
大象长翅膀了??
Prompt: 画一幅李白和杜甫打篮球的图片

Prompt: 画一幅李白和杜甫打篮球的图片
非常奇葩的效果:自动将上一轮的图像用上了,虽然提示词根本没有提上一轮的内容。
新开一轮,同样的提示词,结果如下:

Prompt: 画一幅李白和杜甫打篮球的图片
似乎看到了两三年前生图模型的效果…
看看同样提示词,豆包的生成结果:

豆包网页版效果,Prompt: 画一幅李白和杜甫打篮球的图片
数数也数不对:

Prompt: 画一幅包含四个苹果的静物图
总结:感觉Qwen VLo的画图还是玩具级别,距离真实场景下的使用,还差比较远。
2. 风格转换
尝试了三组图像风格转换,包括吉卜力风格、3D风格、像素风格。

输入图像

Prompt: 将图片变成吉卜力风格

Prompt: 将上面的图片转换成3D风格

输入图像

Prompt: 转换成吉卜力风格

提示词:转换为3D风格

输入图像

Prompt: 转换为真人照片

Prompt: 转换为吉卜力风格

Prompt: 转换为3D风格

Prompt: Prompt: 转换为像素风风格
结论:吉卜力风格,3D风格和像素风格生成的图片还是挺不错的,草稿转真人恐怖谷拉满。
3. 图像编辑
基于这张著名的合影做了一些有意思的图像编辑功能:

输入图像
图像上色:

Prompt: 给图片上色
上色对照片的内容改变太多,而且衣服一部分蓝色,一部分黑色,也有点奇怪。
给这些物理学大佬一人戴一个博士帽如何?

Prompt: 给所有人加一顶博士帽
结果一般般,有一些加了博士帽,效果还可以,有一些没有加上去,图像的内容还是变了,爱因斯坦都不像了。
每个人戴一个诺贝尔奖牌:

Prompt: 给每个人的脖子上挂一个诺贝尔奖牌
这个奖牌效果还可以,除了有一个大佬头变大了很多,有点鬼畜,但三排变成了两排,而且画面变化太大了,人物都没一个认识的了……
露齿微笑:

Prompt: 让画面中的每个人都露齿微笑
这个效果还行.
头变成流汗的emoji:

Prompt: 把每个人的头都变成流汗的emoji
怎么都变成了外星人,还有一个拿着头。。
变动物怎么样?

Prompt: 把每个人的头都变成一种动物
左上角的🦁亮眼,别的都是什么呀…
结论:图像编辑整体差强人意,一些需求会出现鬼畜效果。对于这种真人照片,致命问题是图像变化太影响ID的稳定性了,可能对于卡通图中的形象,画面变一点还能接受,真人图的细节变化,可能就完全像是换了一个人。
4. 检测框

Prompt: 将图片中的人用bbox框起来

有时候Prompt会失效:

5. 分割图
分割功能我还没成功实现过,尝试了几次,要么出来文本回答,要么直接返回一张原图

6. Canny效果图
上面的小狗图片得到的Canny结果如下:

Prompt: 给出图片的canny算子结果图
用OpenCV计算得到的结果如下:

可以看到,并不是完全一样,AI生成的Canny细节更丰富,但一些地方并不是与原图完全对齐(例如鼻子),不知道对结果有多大影响?
7. 其他问题
多次对话后,指令遵循能力下降:

新开一次会话就可以了:
8. 总结
总体来说,比较有意思的是风格转换和图像编辑功能,生图功能不知道为什么做的这么差,检测框和Canny还行,分割图没试出来。
这个模型的发布,说明Qwen团队也尝试对偏向应用的生图、编辑图功能进行探索,但相比豆包等长期积累,有大量用户体验上优化、长期生图效果迭代的选手,目前这个模型还不能让人满意。