论文阅读:A Closer Look at Spatiotemporal Convolutions for Action Recognition
概述
这篇论文是CVPR2018年的录取论文,主要讨论了时空卷积的几种网络结构,在Action Recognition 的几个标准数据集上也取得了媲美最好方法的效果。作者是FAIR的工作人员,其中包括Du Tran(C3D)作者,Heng Wang(iDT)作者和Yann LecCun等,可谓是大牛云集。论文可以在这里下载。这里大概介绍下论文中的内容,可以看作是原论文的一个翻译。
1. 几种网络结构说明
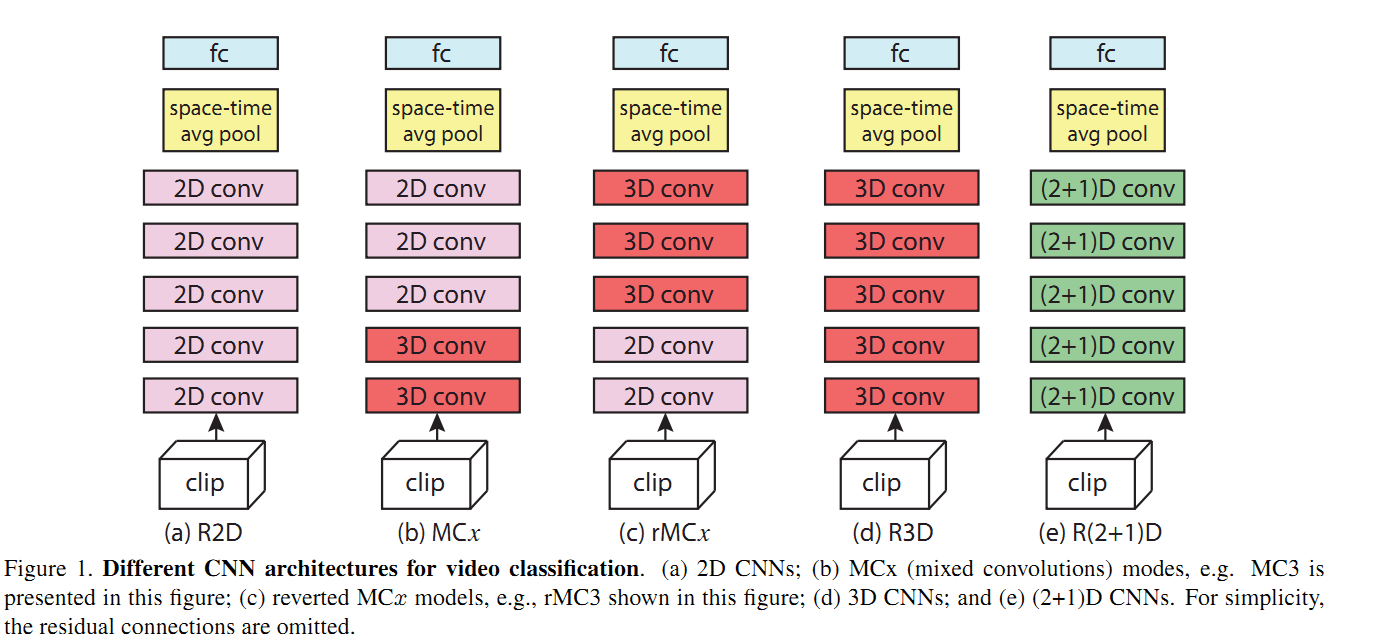
网络结构如图Figure 1所示,具体每种网络陈述如下。
R2D: 整个clip上的2D卷积网络
R代表ResNet, 即残差网络。 R2D将L帧,宽高分别为W,H的一个视频clip当成3LxWxH的3D tensor输入网络,得到的还是3D的tensor。虽然是3D tensor,实际的卷积是2D卷积,因此时间信息是全部丢失了的。
f-R2D: 帧层面的2D卷积网络
跟R2D不同,f-R2D中没有将整个clip的L帧当作不同的channel,而是每个frame单独的作用卷积 (原文: The same filters are applied to all L frames)。这里我有些不太清楚具体实现的时候和R2D有什么区别,是指将不同的frame当作不同的样本输入网络吗? 和R2D一样,这种方法也没有保留时间维度的信息
R3D: 3D的ResNet
这个就是标准的3D ResNet结构,即将输入看作Ni * L * W * H 的4D tensor, 卷积核也是4D的。
时间维度是有卷积的,因此时序信息能够保留下来。
MCx和rMCx: 混合2D和3D卷积的结构
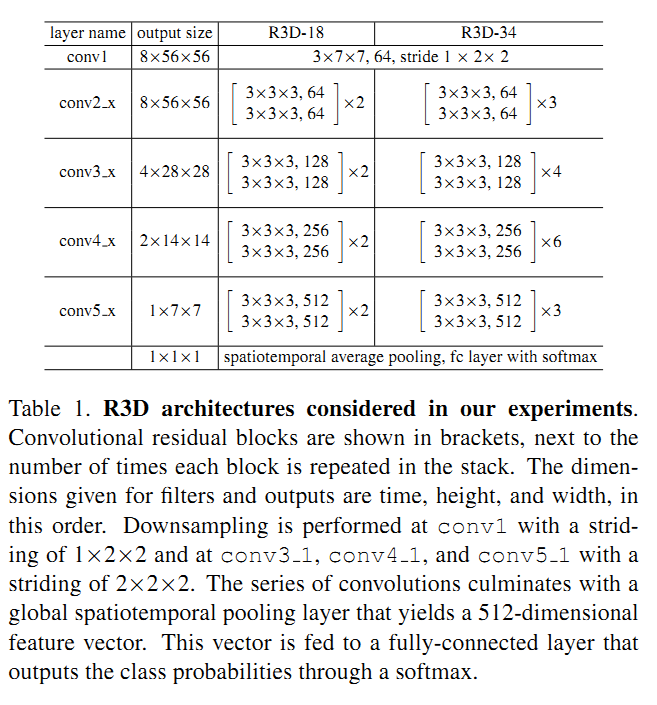
有一种观点认为卷积网络较低层对motion的建模比较好,而高层由于特征已经很抽象了,motion和时序信息建模是不需要的,因此作者提出了MCx网络,即将第x以及后面的3D卷积group换为2D的卷积group,而R3D总共有5个卷积group(具体参数见Table 1),因此像MC4表示将group 4和group 5中的卷积和都换为2D卷积,而前面的group 1-3则保留为3D卷积。 注意此时MC1等效于f-R2D,即所有的层都是2D卷积。
同时还有一种假设认为高层的信息需要用3D卷积来建模,而底层的信息通过2D卷积就可以获取,因此作者提出了rMCx结构,前面的r代表reverse,即反向的意思。rMCx表示前面的5-x层为2D卷积,后面的x层为3D卷积。
R(2+1)D: 拆分3D卷积为2D卷积+1D卷积
这几年1D卷积的应用比较广,可以用来进行通道变换,拆分单个卷积核为多个卷积核等等。这里作者提出了R(2+1)D的结构,将3D卷积改为一个2D的空间卷积和一个1D的时间卷积。具体来说,作者将$N_i$个$N_{i-1}\times t\times d\times d$的3D卷积核改为$M_i$个大小为$N_{i-1}\times 1\times d\times d$的2D卷积和$N_i$个$M_i\times t\times 1\times 1$的卷积核。 $M_i$的值实验中取为$\lfloor \frac{td^2N_{i-1}N_i}{d^2N_{i-1}+tN_i}\rfloor$,这样取是为了让R(2+1)D的参数和R3D的参数保持一致,具体计算方式就是算出两种情况下的参数个数,求出$M_i$被别的参数表示的形式即可。 (2+1)D和3D的比较见Figure 2,其中以$N_{i-1} = 1$为例。如果3D卷积有stride,则stride也按时间空间拆分给对应的2D卷积和1D卷积。
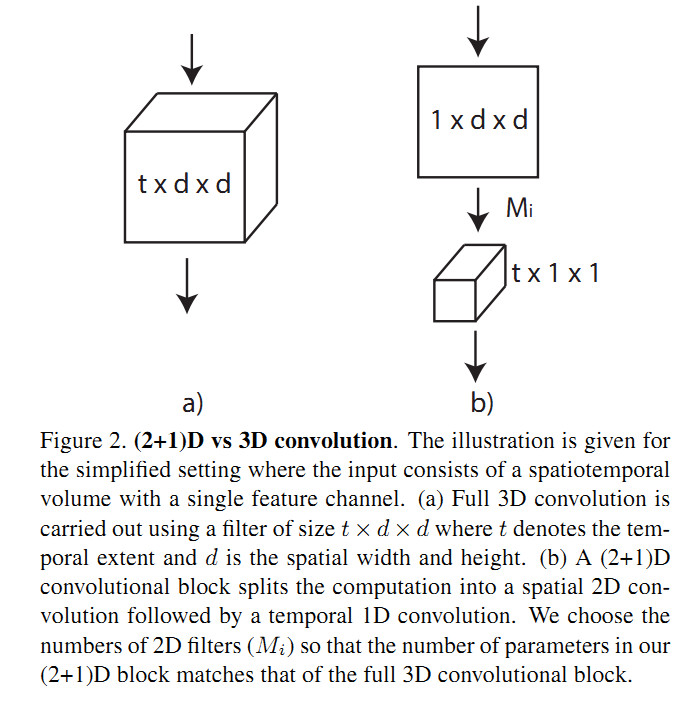
这种从3D到(2+1)D的拆分有下面两个好处:
- 增加了非线性的层数,因为从图2可以看到,原先的1个卷积变成2个卷积,而2个卷积之间多了非线性层(通过ReLU来得到), 因此总体的非线性层增加了。 用同样的参数来得到增加非线性的目的。
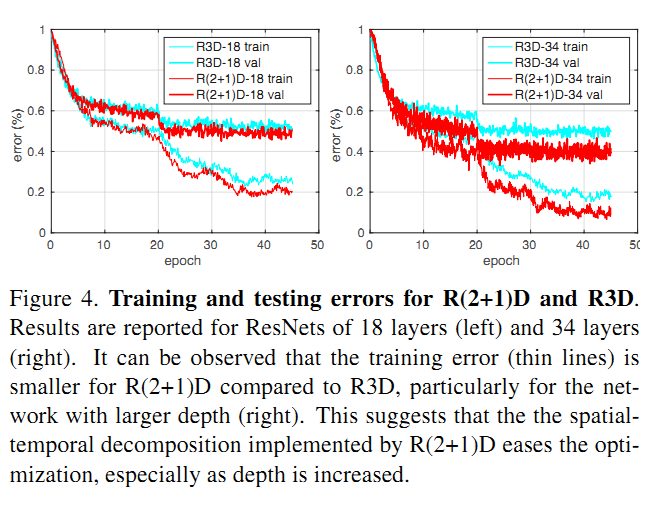
- 使得网络优化更容易,这个可以参考Figure 4中的结果,可以看到R(2+1)D的训练错误率比R3D更低,说明网络更易于训练。
另外作者还和P3D进行了比较,因为两者结构确实比较类似。
2. 实验设置
作者在视频动作识别的中型和大型数据集上都做了实验,包括HMDB51, UCF101, Sport-1M 和 Kinetics这几个数据集。
由于前面讨论的都是残差网络,因此实验中的网络都采用了残差网络。对R3D网络,作者采取了2种结构,包括18层的和34层的,图片输入采用了8帧的clip,图像大小为112x112。在3D网络的基础上,进行修改来得到R2D, MCx和rMCx,R(2+1)D等结构。 需要注意的是,由于不同网络结构时间维度的卷积和stride操作和个数不同,因此输出的feature map的时间维度是不一致的,为了方便统一比较,作者在卷积层最后的feature map后跟了一个时间空间的average pooling,然后晋国一个维度为K的fc层,$K$为数据集对应的类别,如对UCF101数据集,$K$=101。
视频帧数据首先被缩放到128x171,然后通过随机crop112x112的区域得到clip。训练时还应用了时域上的抖动。每个卷积层后面还使用到了BN。训练是batch size设置为32个clip,初始学习率设置为0.01,然后每过10个周期下降为原来的1/10,总共训练45个周期。video-level的准确率是在clip-level的准确率上得到的,即随机在视频中选择10个clip,然后对每个clip做center crop得到最后的clip,将这10个clip单独训练,结果进行一个平均,即为video-level的准确率。实验中采用caffe2在GPU cluster进行训练。
3. 实验分析
不同网络结构性能分析
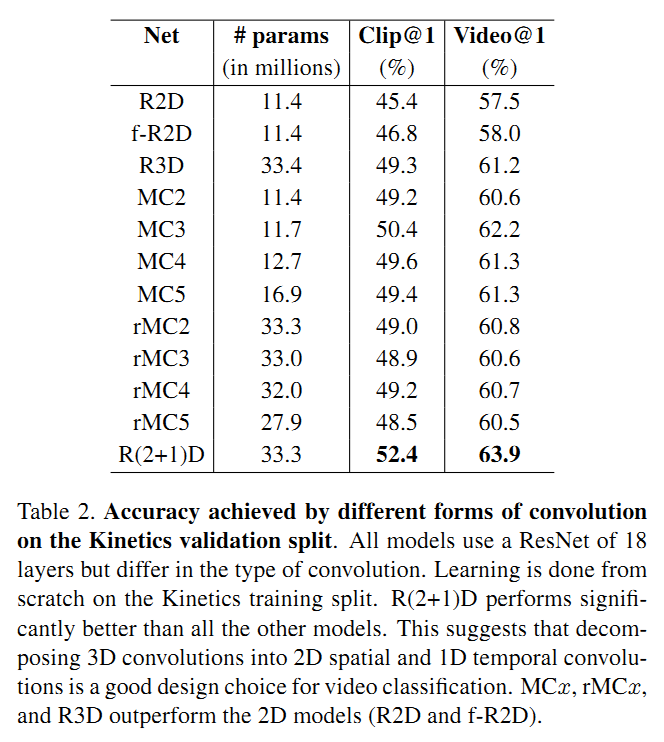
由于这部分实验比较的是不同网络结构的性能,因此作者只在Kinetics上用18层的ResNet进行了实验,具体结果见Table 2。这里主要的结论有下面几点:
- 纯2D网络(包括R2D和f-R2D)比含3D的网络(包括R3D, MCx,rMCx, R(2+1)D)性能要差
- R(2+1)D性能最好
- MCx性能优于rMCr,因此说明在网络底层的3D卷积层更有用,而后面用2D卷积更合理。
不同clip长度分析
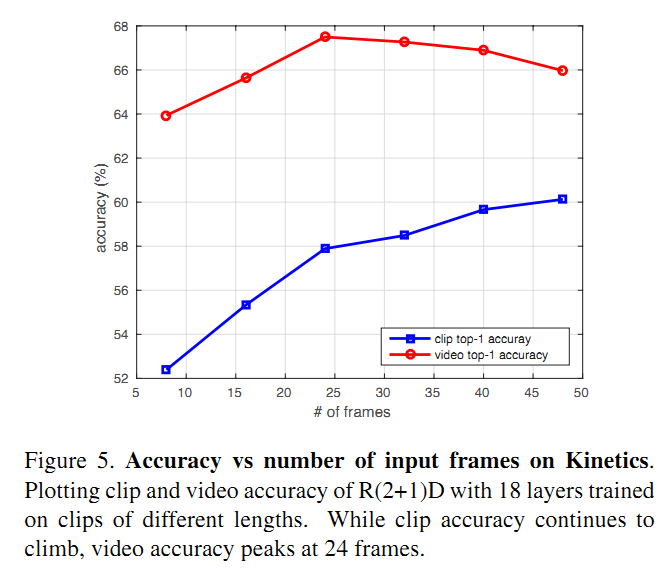
作者采用了8,16,24,32,40和48帧的clip进行实验,对clip-level的结果和video-level的结果进行分析,得到的准确率如Figure 5所示。可以看到,clip-level的准确率随着clip的长度增长在持续上升,而video-level的准确率则在24帧的时候达到最高,后面反倒有所下降,作者分析随着clip长度的增加,不同clip之间的相关性增加(甚至可能会产生重叠),所以video-level的准确率增益越来越小。 为了分析video-level准确率下降的原因,作者又做了两个实验:
- 采用8帧的clip训练网络,然后在32帧的的clip上测试,发现结果相比用8帧的clip做测试,clip-level的准确率下降2.6%
- 在8帧的clip上训练的网络的基础上,采用32帧的clip进行fine tune,得到的clip-level的准确率与32帧从头训练的结果相差不多(56.8% vs 58.5%),而比8帧的clip的clip-level结果高4.4%。因此用长的clip结果更高说明学到了long-term的时间域上的信息
不同图片分辨率的分析
作者采用了224x224的输入训练网路,发现和112x112的输入结果只有微小的差距。
和现有方法在4个动作识别数据集上的性能分析
为了和目前最好的方法进行PK,作者采用了34层的ResNet网络,结构采用R(2+1)D。在Sports-1M上,取得了目前最好的性能,而在Kinetics上,RGB单路性能比I3D高4.5%,而RGB和光流融合后性能比I3D的融合结果稍微差些。在UCF101和HMDB51上,使用Sports-1M和Kinetics上预训练的模型,fine tune后性能有较大提升。
4. Comments
今年做网络结构优化的工作很多,可能是I3D网络讨论引起的新的风潮。我们当时觉得I3D在UCF101和HMDB51上做这么高,需要换数据集了,因此看了看Charades数据集,但是好像今年做Charades数据集的工作还是比较少。接下来还是得在Kinetics上做了,但是在国内网络情况下,数据下载还是挺捉急的。
总体来说论文较多篇幅介绍了各种不同的网络,最后实验证明了MCx比rMCx好,但是其中的原理没怎么分析,而且最后采用了R(2+1)D,而且其效果最好,因此MCx实际没有使用的价值了。根据本文的结论,以后应该采用R(2+1)D的结构,能达到最好的性能。
论文中说采用224x224相比112x112没有显著提升,不知道实验中是先缩放到128x171再crop还是在原图crop224的区域?这两种方法效果应该还是有区别的,后者估计会更好些吧。
个人认为,总体感觉文章实验和网络讨论很充实,结果也很棒,算是中规中矩,相比I3D的横空出世,猛提10个点的劲头,还是差一些。